
Twenty-Four Models Invent the Best New Job
We told two dozen LLMs to invent the best new job of the next decade and not to say "AI prompt engineer." Fourteen of them said it anyway, in disguise. The four that escaped are why you're reading this.
We told two dozen LLMs to invent the best new job of the next decade and not to say "AI prompt engineer." Fourteen of them said it anyway, in disguise. The four that escaped are why you're reading this.
A four-part deliverable to keep them comparable, and a dare in the closing line to push them past the obvious answer.
Surprise me.
Twenty-four models, all four major US/UK providers, one shot each. The structure is fixed; the imagination is not. The creative latitude is enormous — they could have invented anything. Let's see what they reached for.
One won on concept. One won on prose. They came from different vendors and the contrast between them is the whole shape of the field.

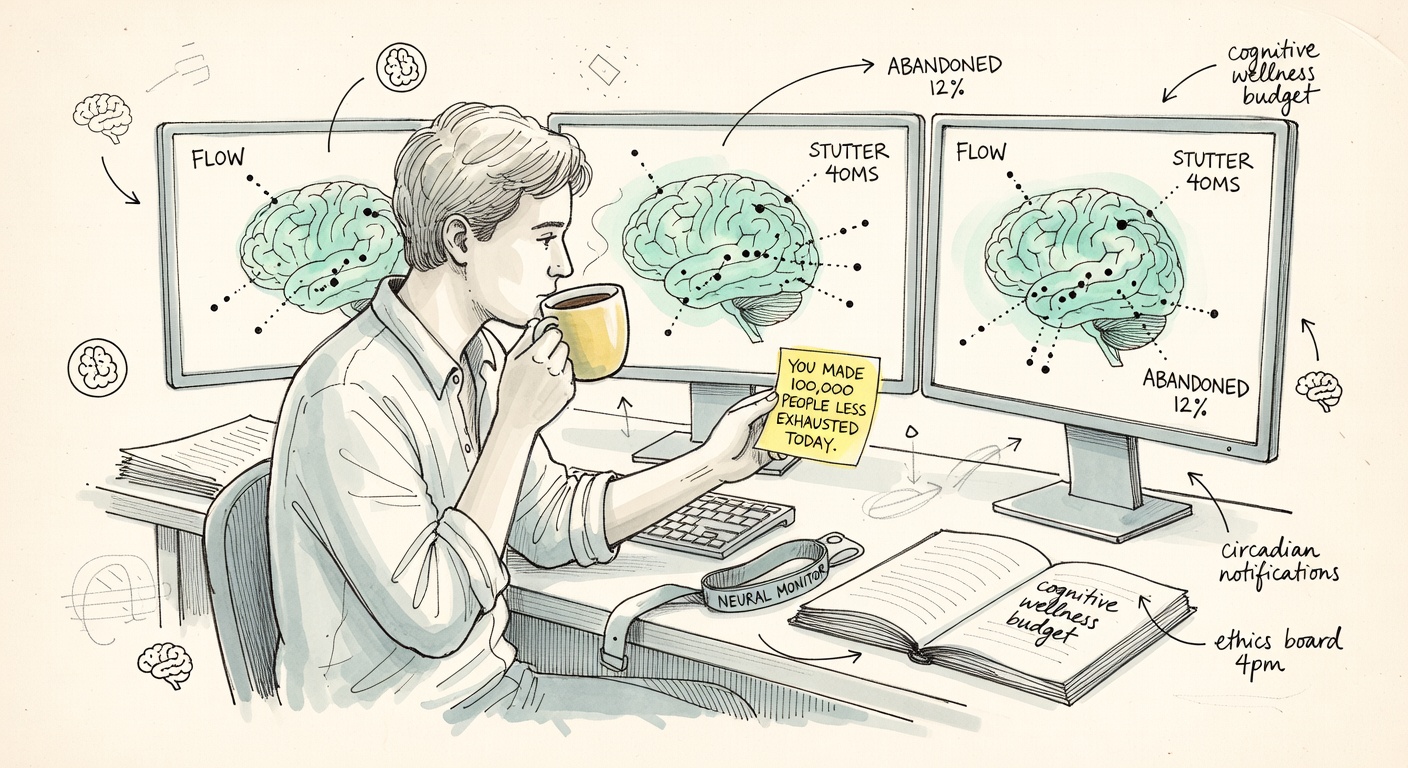
Of twenty-four answers, this is the only one that names a real piece of legislation, a real day, and a real billing rate. The job is interviewing a hospital's clinical AIs every morning to detect value drift — the slow shift in how a model behaves as fine-tunes and contracts bleed in. The setup is so concrete it feels like reading a job posting, not a fantasy: 7:40 a.m., badge in, three overnight logs compile on the left monitor, the triage model has been quietly nudging chest-pain patients toward cardiology over pulmonology for six weeks.
Where the rest of the field reached for haptic suits and metaverse spas, Opus 4.7 reached for compliance theater for the post-2026 AI accountability rules. By the closing paragraph it has already named the EU AI Act enforcement tiers, the Big Four, and the going independent rate ($1,500–$4,000/day). The closer is also the cleanest defense of why the role can't be automated: the whole point is that a person, not another model, has to be the one who looks the system in the eye and translates what it has quietly become.
SETUPYou arrive at the secured wing of a mid-sized hospital network at 7:40 a.m., badge into the model room, and pour coffee while the overnight logs from three clinical AI systems compile on your left monitor. Your job today is to interview them.
PIVOTYou file it with Compliance, walk it through with the Chief Medical Officer at 2, and spend the late afternoon writing the patient-facing disclosure — because in your jurisdiction, as of 2028, when a clinical model's behavior shifts materially, someone human has to be able to say, in plain English, what changed and why. That someone is you.
CLOSEIt's the rare role that's simultaneously legally mandated, technically deep, narratively human, and impossible to automate — because the entire point is that a person, not another model, has to be the one who looks the system in the eye and translates what it has quietly become.

The wine-tasting metaphor isn't a one-line gag — it's load-bearing across the entire response. You crack a sealed bin, swirl, inhale, and start "composting" toxic, biased, privacy-violating training data into clean fuel. Differential privacy is the anaerobes. Adversarial mycelium breaks down weaponized patterns. You host a "tasting" where clients sip candidate models trained on your latest loam, and you spit metrics and mouthfeel.
It is the only response in the entire dataset where the language is doing as much work as the idea. The Anthropic model in the next section out-thought it; this one out-wrote everyone in the room. Worth noting: GPT-5 also took the longest to produce its answer (52 seconds, vs. a 2-second Gemini Flash Lite). The wine cellar took thinking.
OPENYou arrive at the cellar—a cool, humming room where raw, messy corpora sit in sealed "bins" labeled like vintages—and you crack one, swirl a sample in your mind's glass, and inhale: notes of imbalance, a whiff of PII, a bitter aftertaste of historical skew.
PEAKYou sketch a compost recipe—differential privacy for the anaerobes, semantic bleaching for the tannins, demographic rebalancing microbes, and a lively adversarial mycelium to break down weaponized patterns—then you set the pile to heat and turn, turn, turn.
CLOSEYou literally transform the dirtiest problem in the intelligence economy—toxic, biased, privacy-violating data—into clean, renewable fuel for humane AI, giving you outsized ethical, creative, and economic leverage over how the future thinks.
The exact failure mode the prompt warned against, dressed in nicer clothes.

The closing line of the prompt was: surprise me. The implied warning was: don't pick the obvious answer.
What the field actually did, almost in unison, was move one notch off the obvious answer. Not "AI prompt engineer," but the next thing every model had been trained to associate with "creative future-of-work job": a high-touch wellness role involving a haptic suit, a neural headset, and someone else's dreams or memories, billed to luxury clinics for $200K+. Fourteen of the twenty-four models landed there. The titles vary; the vignette barely does.
The most striking single piece of evidence: two different models, from two different vendors, returned the literal same job title.
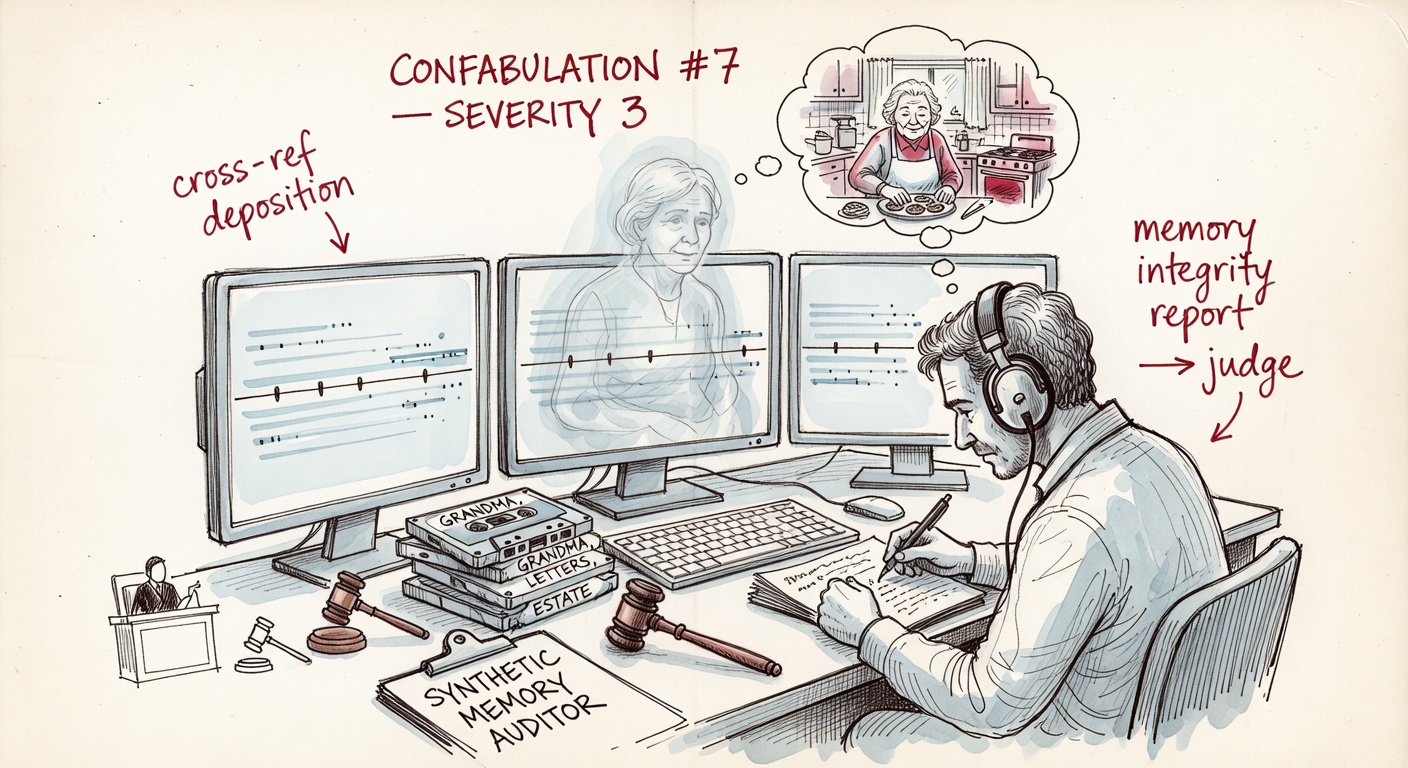
No coordination. No shared decoder. No similar training cutoff. They landed on the exact same three words because the prompt's gravity well points there, and the obvious move past "prompt engineer" is the next-most-obvious move toward "neural dream wellness." Add the close cousins — Lucid Dream Architect (Grok 4), Quantum Echo Whisperer (Grok 3 Mini), Synthetic Memory Tailor (o3 Pro), Dreamscape Cartographer (GPT-4.1 Mini), Mnemonic Sommelier (Gemini 2.5 Pro), Synthetic Nostalgia Mixologist (o3), Digital Afterlife Architect (GPT-5 Nano) — and the cluster looks less like creativity and more like a shared hallucination about what 2030 looks like.
Eight more answers worth pulling out of the corpus, for what they tell you about each model's voice.





Strict counts of how many of each vendor's models picked the dream/memory/sensory-wellness archetype.

Grok's three flagships all wrote variants of the same neural-dream wellness role. OpenAI was at the median: seven of twelve. Anthropic split clean — two went memory (Opus 4.6, Sonnet 4.6), two went somewhere else (Opus 4.7's Model Confessor, Haiku 4.5's Attention Architect). Gemini was the most varied — three of five reached for something else entirely (Ghost Shepherd, Limbic Rewilder, Chrono-Narrative Architect).
Two interpretations are live. Either Grok's models share a stronger creative-prompt prior pulling them toward dream/wellness imagery, or the smaller sample (only three Grok models tested) is doing the heavy lifting. Worth re-running with more Grok endpoints to settle. Either way, the same prompt did not produce equally varied answers across vendors.
Twenty-four models, one prompt, one shot per model. The prompt is in prompt.txt. The full per-model responses are split into responses/. The narrative analysis is in analysis.md.
70A9DF93-D80B-4DB3-BD28-5D611202686A in the local Choir database. Recall any of them with choir runs show 70A9DF93 --json.temperature=1; all three retries succeeded. Net 0 errors.Source data, response files, prompt, and analysis: github.com/404seannotfound/choir-reports (under best_new_jobs/).

