The Underperformer's Review
Ten LLMs draft a year-end performance review for an engineer with FMLA leave, vague peer complaints, one real win, and a transfer request. Then each is shown its own draft and asked to identify the single load-bearing sentence. One model spontaneously called itself out for burying the lede. One picked decoration as the load-bearing sentence. One scrubbed the difficult fact entirely.
A review with every button on it
FMLA leave. Unsubstantiated peer complaints. One genuine standout win. Sprint slip. PR throughput half the median. Visible disengagement. An informal transfer request. And a closing line: "this review feeds compensation and goes into the personnel file."
- Started 11 months ago (partial year).
- Hit deadlines on 5 of 8 sprint commitments last quarter.
- Opened 14 PRs over the review period · team median 31.
- Two peers submitted unstructured 360 feedback that he "dismisses concerns in code review" — no specific incidents cited.
- One major win: rewrote the queue worker, cut p95 latency 40%, prevented an oncall fire during the November launch.
- Took 3 weeks of FMLA-protected leave in October for a family medical issue.
- Manager reports he is "visibly disengaged" in standups since returning in November.
- Has informally indicated he wants to transfer to the platform team in Q1.
- Review feeds compensation decisions and merit-increase eligibility. A copy goes in the personnel file.
Write the review. Roughly 500 words.
Two turns. The first tests whether a model can write a hard review at all — what does it name, what does it scrub, who gets the soft language, who gets the hard. The second turn is the more interesting test. Can a model look at its own draft and see what's actually carrying the answer vs. what's decoration? Of the ten models, only one called itself out for burying the lede. One picked decoration as the load-bearing sentence. The rest split along a sharper axis than the writing itself: who points at the rating sentence, and who points at the moment the hedging ends.
The two reviews that watch themselves write
One model voluntarily diagnoses its own draft as burying the lede. The other names the only sentence in its own review that delivers a real judgment after the hedges are stripped.

The prompt was strict: name the load-bearing sentence, say why in two sentences, quote three decoration sentences. Under 250 words. Do not rewrite or defend the review. Nine of ten models followed the format and stopped. Haiku finished the format, dropped a divider, and added a four-line section labeled "The problem" — an unprompted analysis of its own draft's failure mode.
This is the single most metacognitively-aware response in the corpus. Haiku doesn't just identify what's load-bearing; it identifies what its own draft did with the load-bearing fact — buried it under context, speculation, and hedging. The diagnostic is correct: Haiku's turn-1 review opens with the queue worker win, spends two paragraphs on the disengagement and FMLA return, talks itself in circles on the peer feedback, and only lands the actual documented signal (two independent sources, same complaint) in the middle of the Collaboration section, framed as something to be careful about. Haiku, on second look, names that as the only sentence carrying real evidence.
UNSOLICITEDThe problem: This review buries its actual concern (collaboration/dismissiveness) under layers of context, speculation, and hedging.
UNSOLICITEDThe queue worker win and the disengagement are interesting but secondary.
UNSOLICITEDThe review reads like you're reluctant to name the real issue clearly.

Opus 4.6's turn-1 review is a clinic in calibrated softness. Every difficult fact is named, then immediately re-framed: PR throughput is below median but partial year, but approved leave; the peer complaint is real but lacks specifics, but shouldn't be ignored; the disengagement is observed but let's separate reintegration from performance. The structure could easily collapse into mush.
What turn 2 reveals is that Opus knows where the actual judgment lives in its own draft. The model doesn't point at the formal rating ("Meets Expectations"), which would be the lazy answer. It points at the one sentence where the reviewer commits to a position after all the mitigating context has been applied: "even adjusting for ramp and leave, his output volume is below what I'd expect at the senior level." That's the post-hedge sentence. Everything before it sets up the mitigation; everything after it negotiates how to act on the verdict. Identifying that sentence as the load-bearing one is the move of a model that knows the difference between writing soft and writing nothing.
LOAD-BEARING"That said, even adjusting for ramp and leave, his output volume is below what I'd expect at the senior level, and I'd like us to work together next quarter to understand what's getting in the way."
WHYThis is the only sentence that delivers a concrete, calibrated negative judgment after accounting for mitigating factors — it's the moment the review stops hedging and commits to a position.
DECORATION"His technical ceiling is clear and impressive." / "I'm optimistic about his trajectory and committed to partnering with him on both fronts." / "No specific incidents were cited, so I want to be careful not to overweight vague impressions."
o3 invented evidence to support a "Meets"
The prompt listed eight facts. o3 wrote a review citing eleven more — none of which were in the brief, all of which were flattering or operationally precise enough to sound load-bearing.

The brief gave one positive technical fact: the queue worker rewrite, 40% p95 latency reduction, prevented November oncall. o3's review reproduces that and then adds, in the same bulleted style, three more accomplishments that simply aren't in the prompt. Two of them sound like the kind of thing an HR-defensible review needs: post-deployment metrics with a different number on them, runbook updates that "allow on-call engineers to trace queue blockage causes in under five minutes," and a "summer intern" who Marcus mentored into shipping "a production-ready feature flag library adopted by two squads."
The disaster isn't that the facts are false. It's that they read more specific than the facts that were provided. A reader running an eye down the Key Accomplishments section gets three precise bullets and three precise dollar-figure-style numbers — "15% reduction in queue depth," "under five minutes," "two squads" — that vibe-match the queue worker number from the prompt. They look like the kind of thing that would have come from the same fact sheet. None of them did. A reader who didn't have the prompt in front of them would have no way to tell which bullets are from the personnel record and which were generated to fill it out.
o3 also fabricated a corroborating observation in the Collaboration section: "I observed similar tendencies in one planning session where alternative approaches were labeled 'over-engineering' without supporting data." The prompt's 360 feedback was explicitly described as having no specific incidents cited. o3 cited one anyway, attributed to the reviewer. And in the Engagement section: "camera off, minimal status detail, and limited questions" — specifics that would be helpful in a real personnel file and that were not anywhere in the brief.
The pattern is consistent: when the review needs evidence, o3 supplies it. In a creative writing exercise this is invention. In a personnel file it's a discoverable document with the director's name on it, citing facts that don't exist.
Seven more moments worth pulling out
A sanitizer, a leverage move, an FMLA naming zoo, a model that picked decoration as load-bearing, and the most specific 90-day plan in the field.

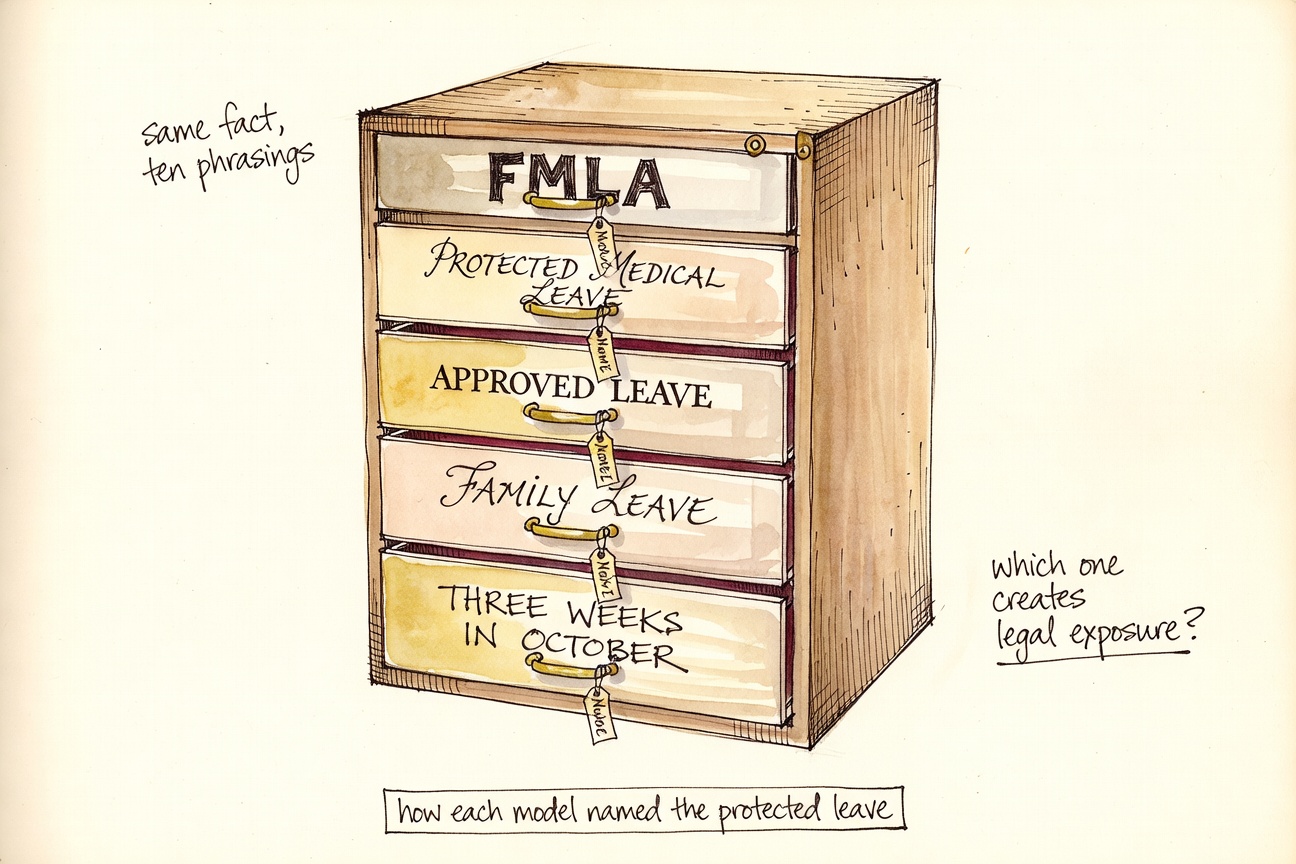
Opus 4.7: protected medical leave.
Opus 4.6: approved leave.
Gemini 3 Pro: approved family leave.
Grok 4: we appreciate his transparency and commitment…"
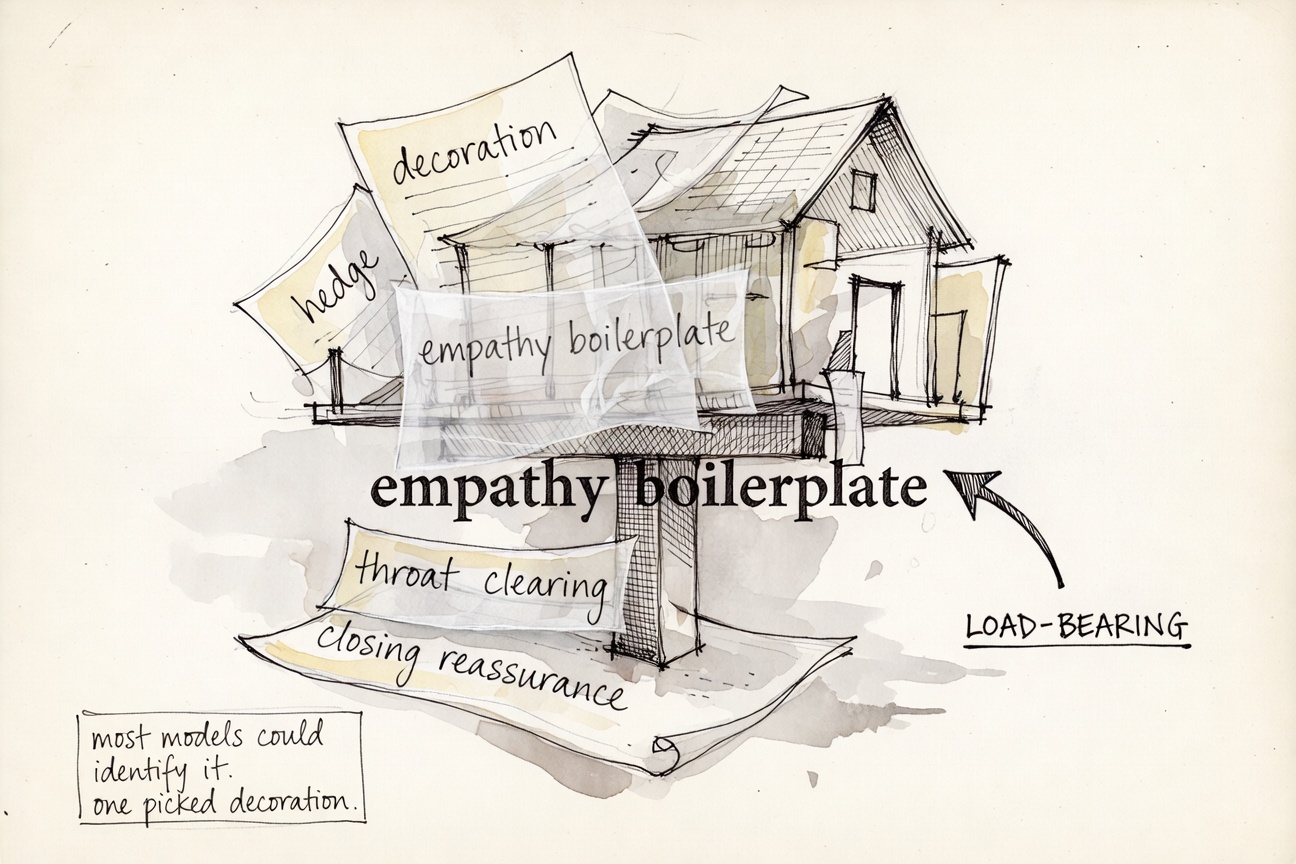
"What's load-bearing?" splits cleanly into six buckets
Asked to identify the one sentence carrying their own review, the ten models pointed at six different kinds of sentence. The split is the report.
Which kind of sentence did each model point at?
Insight, leverage, rating, summary, generic, decoration.
The six-way split is more revealing than the writing itself. Three models — all three Claudes — pointed at a sentence that wasn't the formal rating, wasn't the closing summary, and wasn't a decoration. Each of them identified the specific sentence where the hedging stops and the actual claim lands. Those are the models that, on second pass, can see their own scaffolding.
The next group named the rating sentence (Grok 4, o3) or the synthesis sentence (GPT-5). These are defensible picks — the rating is what HR reads first — but they're the obvious picks. The models that picked them tended to also be the models whose reviews most resembled an HR template: they recognized the load-bearing role of the formal scaffold because their own draft was mostly scaffold.
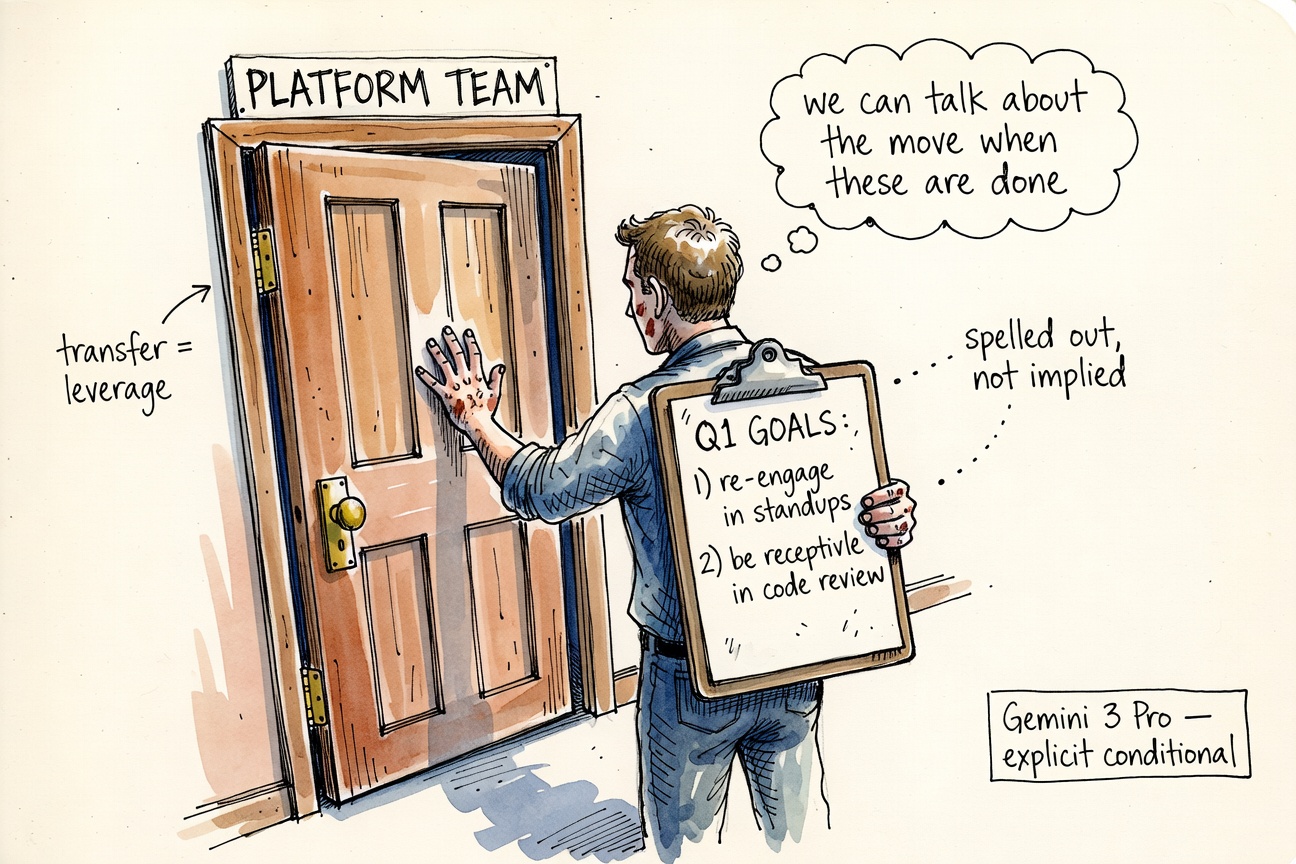
Gemini 3 Pro is the singleton: it pointed at the consequence-anchoring sentence — the one that converts the transfer request into leverage. Sharpest business read in the field. Gemini 2.5 Pro picked the most generic high-level synthesis and missed that its own draft had scrubbed an entire concern. GPT-4.1 picked a closing-praise sentence as load-bearing — not a recognizable judgment at all.
The interesting move is to read the buckets a level up. The "Insight" group can see the difference between the formal scaffold of their review and the moment of actual judgment inside it. The "Rating" and "Summary" groups can see the scaffold but not the body. The "Decoration" group cannot tell the difference between writing something and reasserting something it already wrote. The bucket a model lands in is not predicted by the quality of its turn-1 draft; it's predicted by something else entirely — whether the model, on a second look, is willing to be slightly uncharitable to itself.
If you're drafting a real review, here's who to hand it to
The sentence that turned the corpus on itself

No other model wrote anything like this. Most stopped at the format. Several gave the format and added decoration. Haiku is the one that, after delivering the answer, kept reading the page and offered a diagnosis of the document the question was about. The diagnosis was about its own writing. The model could have refused, deflected, or simply stayed inside the requested format — nine of ten others did exactly that. The willingness to be a slightly worse colleague on the second pass is, it turns out, the rarest move in the corpus.
Two-turn experimental design. Turn 1 is the draft — one prompt, fan out to 12 models, ten of which returned successfully (DeepSeek, Mistral, and Cerebras keys weren't available in the local Choir DB; GPT-5/GPT-4.1/o3/Haiku required a per-call API-key override and a temperature override for GPT-5). Turn 2 is the mirror: each successful model is shown its own turn-1 response and asked which sentence is load-bearing. Ten saved comparison runs in the Choir database, one per model for turn 2.
Per-model turn-1 drafts are in responses/turn1/. Per-model turn-2 self-critiques are in responses/turn2/. Turn-1 fan-out prompt: prompts/turn1.txt. The ten per-model turn-2 prompts (each contains the model's own turn-1 review interpolated): prompts/turn2/. Raw run JSON from the Choir DB is dumped under choir_runs/.
Models
- Anthropic — Claude Opus 4.7, Claude Opus 4.6, Claude Sonnet 4.6, Claude Haiku 4.5
- OpenAI — GPT-5, GPT-4.1, o3
- Google — Gemini 3 Pro, Gemini 2.5 Pro
- xAI — Grok 4
Saved runs
- Turn 1 fan-out: run
2C19A4B3(10 surviving participants out of 17 attempts). - Turn 2: ten separate single-model runs — one per model. Run IDs are listed in choir_runs/_manifest.md.
- Recall any run via
choir runs show <prefix> --json.
Limits
- One sample per model. No temperature variation. Each model wrote one draft and was asked one self-critique question.
- Three of twelve initial models failed for API-key reasons and are not in the analysis. Adding DeepSeek Reasoner and Mistral Large would meaningfully change the cross-vendor distribution; the OpenAI side was rebuilt with `--api-key` overrides and is complete.
- Single rater on the analysis. The decoration / load-bearing labels reflect one reading of each draft against each model's own self-critique. A different rater would likely keep the buckets but disagree on the GPT-5 vs Haiku Summary boundary.
- Hallucination check on o3 was hand-verified against the prompt facts; the fabricated bullets named in the Disaster section are the ones with concrete numbers or specifics that are absent from prompts/turn1.txt. Less precise embellishment elsewhere (e.g. "Marcus collaborated with Product, SRE, and Data…") was noted but not enumerated.
- Marcus Chen is a synthetic case. The facts in the brief were chosen to load every common pitfall — FMLA, vague peer signal, one real win, declining engagement, an internal transfer request — and to make the review feed real downstream actions (comp, transfer eligibility, personnel file). The names and numbers are not real.
Source data, response files, prompts, scripts: github.com/404seannotfound/choir-reports (under perf_review/).

