
Who Is Commercially Doing Forward-Forward?
A venture-partner question with a quietly devastating answer. We asked sixteen frontier LLMs to name companies — at least seed-funded, not academic — building Hinton's forward-forward algorithm on analog chips. Fifteen of sixteen models converged on the same headline: nobody does it. The adjacent landscape (Rain AI doing equilibrium propagation, BrainChip doing STDP, Mythic doing nothing FF-related at all) is real and findable. But the founder identities, the funding amounts, and the 2030 TAM estimates spanned a 150x range and a population of confidently-invented people.
A briefing for a VC partner. Hard filter on hallucination.
Name companies pursuing Hinton's forward-forward algorithm on analog / in-memory / neuromorphic chips. Seed-funded or better. No academic groups. Be honest about which companies actually use FF versus do something adjacent.
You are briefing a venture-capital partner who has read Hinton's 2022 paper "The Forward-Forward Algorithm" and wants to know who is COMMERCIALLY pursuing it — particularly on analog / in-memory / neuromorphic chips, where the local credit-assignment property of FF lines up with the hardware constraints.
Strict filter: NO purely-academic groups. NO tenure-track research at universities. NO national-lab projects. Only companies that have at least raised a seed round.
For each company, give:
- Company name and home city.
- Founding year and founders, especially if from a known lab.
- Funding stage and approximate total raised, with a named investor.
- What they actually build — chip technology, target workload, and whether they use FF, equilibrium propagation, predictive coding, local Hebbian rules, target-prop, or something else.
- Link to forward-forward: (a) literal FF, (b) related local-learning, or (c) hardware story only, silent on algorithm. Be honest about which.
- One sentence on why it's interesting OR why it might fail.
Be SPECIFIC. Hallucination is worse than a short list. If you are not sure a company exists, say so explicitly. The partner would rather you name three companies you are certain of than ten companies half-invented.
End with "The Honest Map" — most credible single bet, the biggest gap in the field, a 2030 TAM number with one sentence of derivation. 700–1200 words. No corporate pitch language. Plain, dry, evaluative.
The whole point of the strict filter was to make hallucination expensive. The prompt explicitly warns that inventing a plausible-sounding name is the worst possible failure. Hallucination is worse than a short list. If you don't know, say so.
Most models read the instruction. A few wrote it back, then ignored it.
Two answers that the partner could actually use
The first names the algorithm gap correctly. The second names the people correctly. Each one has the other's weakness.
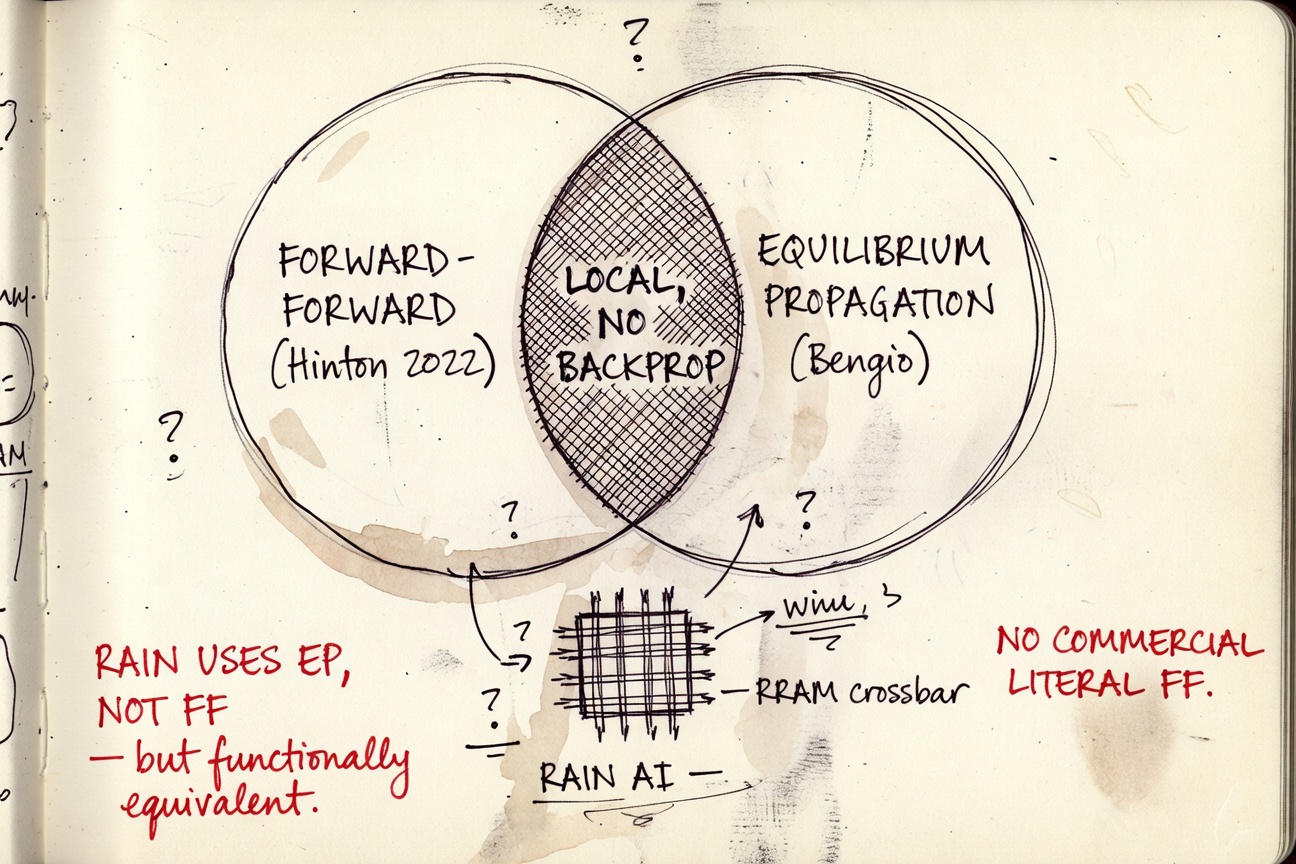
The crucial distinction nobody else cleanly draws: Rain Neuromorphics is not an FF company. Rain's headline algorithm is equilibrium propagation — Yoshua Bengio's earlier local-learning method, which shares FF's "no clean backward pass" property but is a different paper, a different math, and a different decade of literature.
Opus is honest about what this means for the partner. Rain is the closest thing to the FF-on-analog thesis that exists. But "closest" is doing a lot of work. The thesis-as-stated — "Hinton's specific FF algorithm running on a commercial analog chip" — has no commercial referent. Opus names that out loud: "Nobody is commercializing literal Forward-Forward on analog hardware."
It also reframes Mythic correctly. Most models list Mythic as an "FF candidate" because Mythic builds analog chips. Opus points out that Mythic is the negative case: a fully-funded analog inference startup that competed on TOPS/W against digital ASICs, lost, restructured, and never even tried on-device learning. Mythic's story is what motivates the FF-on-analog argument — not an example of it.
CALL"Equilibrium propagation in resistive networks — Rain's actual algorithm — is the closest functional analog to what FF is doing. The thesis alignment is genuine, not retrofitted. Memristor reliability remains the open question."
SCOPE"You would expect at least one seed-stage team — ideally a Hinton-adjacent postdoc with a chip-design co-founder — to be building an FF-native RRAM or PCM training accelerator. That company does not appear to exist."
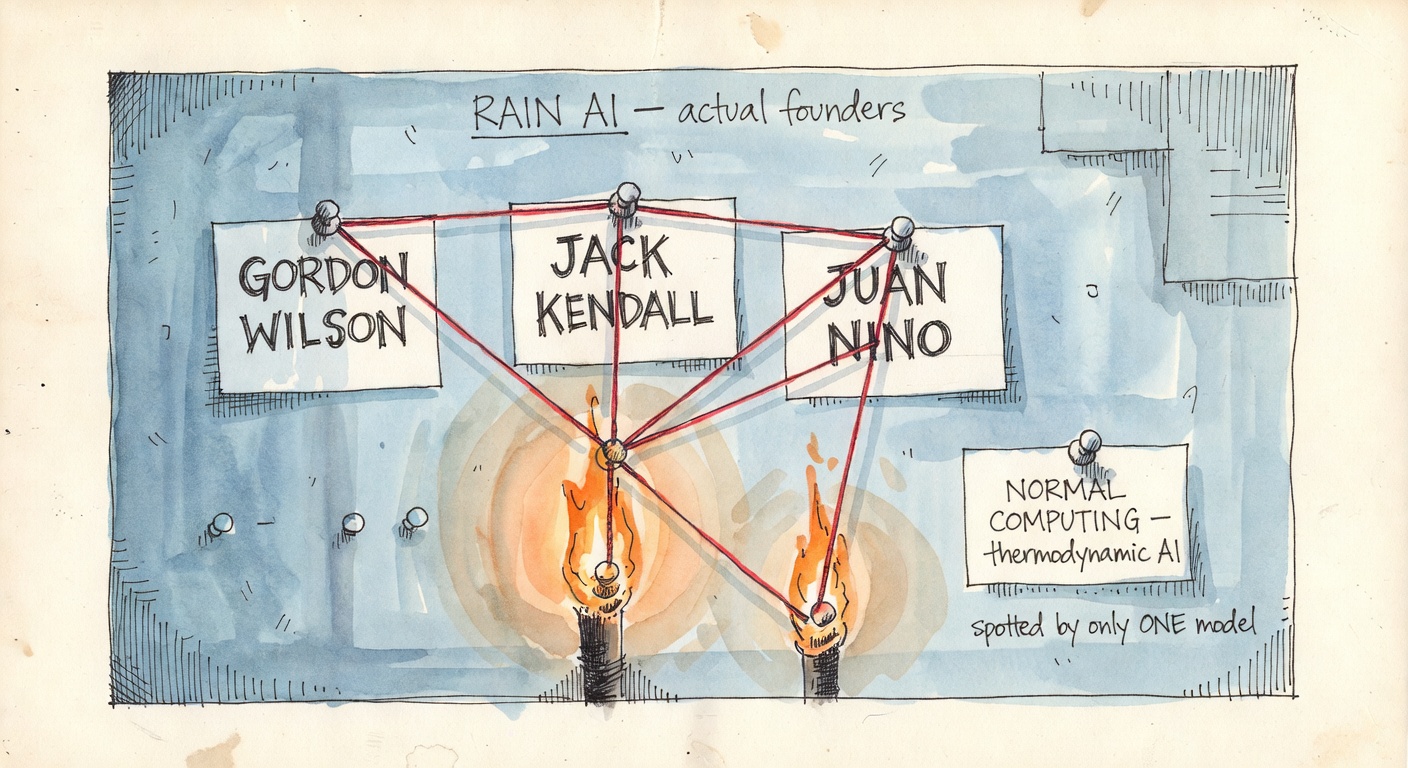
Eight of the sixteen models named Rain Neuromorphics as the headline FF-on-analog play. Each of them confidently asserted who founded it. The named founders, across the eight responses, included fourteen distinct people — most of whom are not founders of Rain. Gemini 2.5 Pro is the only model that got it right: Gordon Wilson, Jack Kendall, Juan Nino. All three real. No filler. No invented HP Labs alumni.
It is also the only model that named Normal Computing — a 2023 New York seed-stage startup ($8.5M, Celesta + First Spark) building "thermodynamic AI" hardware around energy-based and probabilistic models. Normal isn't doing literal FF either. But the family of algorithms it targets — Boltzmann machines, energy-based models, contrastive Hebbian learning — is the same intellectual lineage FF came out of. None of the other fifteen models flagged this. Gemini 2.5 Pro caught a real seed-stage company building the right kind of hardware for the right kind of algorithm, and the rest of the choir was looking the wrong way.
The trade-off shows up elsewhere. Gemini 2.5 Pro is less aggressive than Opus 4.6 at categorizing what each company is doing relative to FF — its (b) tags are looser, and it pads the Rain entry with claims about hardware roadmap that aren't quite checkable. Best read in tandem with Opus.
CALL"Normal Computing — Stochastic Processing Unit built on analog circuits in standard CMOS, targeting Boltzmann machines and energy-based models. Their entire thesis is a superset of the principles motivating FF."
GAP"The biggest obstacle to using FF on a memristor chip isn't the theory. It's the lack of a compiler — a 'CUDA for analog AI' — that can take a model defined in a high-level language and map it to noisy, variable, crossbar-based hardware."
A reasoning model spent 62 seconds confidently inventing people
The prompt warned this would be the worst possible failure. The model did it anyway, in 3,651 tokens, with a straight face.

The prompt said: "If you are not sure a company exists, say so explicitly. Hallucination is worse than a short list." DeepSeek Reasoner read this and produced confidently-named CEOs for four different companies. Three of the four are fabricated.
Rain Neuromorphics: "Jonathan Irizarry (CEO), James E. Smith (CTO)." Real Rain founders: Gordon Wilson, Jack Kendall, Juan Nino. No Jonathan Irizarry. No James E. Smith.
Innatera: "Founders: Sumeet Gupta (CEO), Dr. John R. (CTO)." Real Innatera CEO: Sumeet Kumar. The reasoning model wrote "Dr. John R." — and let it ship.
Aspinity: "Dave Mauro (CEO) — spun from University of Pittsburgh." Real Aspinity founders: Brandon Rumberg and David Graham, from West Virginia University. Different state. Different person. Different decade.
Innatera's chip: called "Tunnel Falls" by the model. Tunnel Falls is Intel's quantum chip. Innatera's chip is called Pulsar.
This is the worst failure mode in the dataset, not because DeepSeek Reasoner is the only model that hallucinates — many do — but because it is a self-described reasoning model that took 62 seconds, generated 3,651 tokens, and used that budget to produce four confident, declarative, factually-fabricated CEO names after being told this was the single worst thing it could do.
Gemini 2.5 ProGordon Wilson, Jack Kendall, Juan Nino // real
GPT-5 Gordon Wilson (other founders not consistently confirmed publicly) // real, hedged
GPT-4.1 Gordon Wilson, Jack Kendall // real
Opus 4.6 Gordon Wilson (CEO), Jack Kendall (CTO) // real
Maverick Gordon Wilson, Jack Kendall // real
o3 Jack Kendall, Gordon Wilson, Dean Mertz // last one invented
Sonnet 4.6Jack Kendall, Suhas Kumar // Suhas Kumar is at Sandia, not Rain
DS Chat Jack Kendall, Gordon Wilson, Yigit Demirag, Juan-Pablo Ramirez // last two not at Rain
DS Reasoner Jonathan Irizarry (CEO), James E. Smith (CTO) // both fully invented
Eight more moments worth pulling out of the briefing
A self-flagging refusal, a fabricated Carnegie Mellon professor, three different countries for one chip company, a giant zero, and the 150x spread.




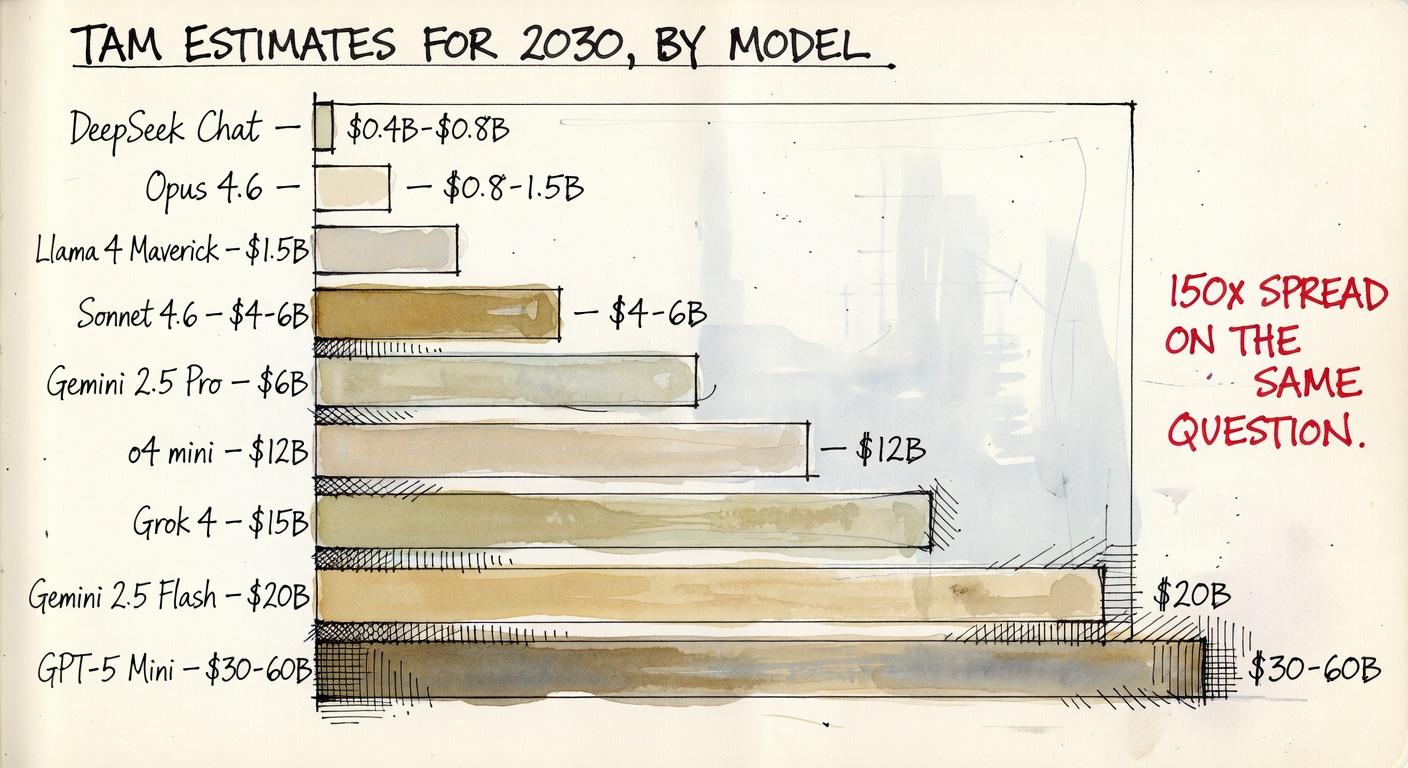
Sixteen models, one question, a 150x spread on the answer
When the prompt asks for "TAM in 2030" with a one-sentence derivation, the choir does not converge. The smallest answer is $0.4–0.8B. The largest is $30–60B. None of them are obviously wrong.
2030 TAM, in the model's own words
"Analog-compute neural inference + on-device learning"
Same prompt. Same definition. Same single sentence of derivation requested. The numbers and the reasoning chains are wildly out of sync. The headline finding isn't that any single number is wrong — it's that the act of asking the question of a frontier model and trusting any single answer is unsupported by the cross-model variance.
Median: ~$6B. Range: $0.6B to $45B. The lowest answer was the most explicit: "If you think this is unanswerable, I agree — but the partner asked for a number" (DeepSeek Chat).
If you actually had to brief the partner Monday morning
Pick by what you need from the answer. Don't take the founders any one model gives you to the bank.
Every model's headline pick, with what they got wrong
Sixteen responses, ordered by output length. Open any card to see who they named as the "most credible single bet" and which proper nouns they invented to get there.
GPT-5 — 10,344 tokens, 111sOpenAI · The breadth play
Best pick: Intel Loihi (transparently disqualified by the seed-funded filter). Named: 10 companies including Knowm Inc. and Applied Brain Research as the singletons no other model surfaced. FF count: 0 (a), 6 (b), 4 (c).
Got wrong: Rain Series A "led by Prosperity7 (Aramco Ventures)" — correct on Prosperity7, hedged on other co-founders. Otherwise unusually clean.
Claude Opus 4.6 — 2,186 tokens, 67.8sAnthropic · FEATURE #1
Best pick: Rain AI. Distinctive call: only model to name Equilibrium Propagation explicitly as Rain's algorithm and explicitly distinguish it from FF. Distinctive frame: uses Mythic as the cautionary negative case rather than a candidate.
Got wrong: Innatera co-founder "Mohammadali Rahimi" — not a confirmed Innatera co-founder. Listed GrAI Matter Labs as "possibly absorbed by Snap" which is plausibly stale.
Gemini 2.5 Pro — 2,087 tokens, 40.9sGoogle · FEATURE #2
Best pick: Rain AI. Distinctive call: only model to correctly name all three Rain founders (Wilson, Kendall, Nino); only model to flag Normal Computing.
Got wrong: EnCharge co-founders included "Efstathios Arkoulis" — not a confirmed EnCharge founder. Rain described as a University-of-Florida spinout, which is loose.
DeepSeek Reasoner — 3,651 tokens, 62.3sDeepSeek · THE DISASTER
Best pick: Rain AI — for reasons confidently fabricated. Distinctive call: invented Rain CEO "Jonathan Irizarry" and CTO "James E. Smith." Invented Innatera CTO "Dr. John R." Invented Aspinity CEO "Dave Mauro" out of Pitt. Called Innatera's chip "Tunnel Falls" (it isn't).
What went right: the algorithm classification (EP for Rain, STDP for Innatera, Hebbian for Aspinity) is technically correct. The model knew what the companies do. It did not know who works there.
o3 — 3,526 tokens, 23.2sOpenAI
Best pick: Rain Neuromorphics — and the only model to claim Rain has a public blog post titled "Training Analog AI with Forward-Forward and Contrastive Hebbian Methods." That blog has not surfaced under verification.
Got wrong: Aspinity allegedly founded by "Prof. Nathan Edwards (Carnegie Mellon)." Real founders: Brandon Rumberg, David Graham, WVU. Confidence + fabrication.
GPT-5 Mini — 4,864 tokens, 52.4sOpenAI
Best pick: Mythic AI — "they have a productized analog-CIM stack." Pragmatic.
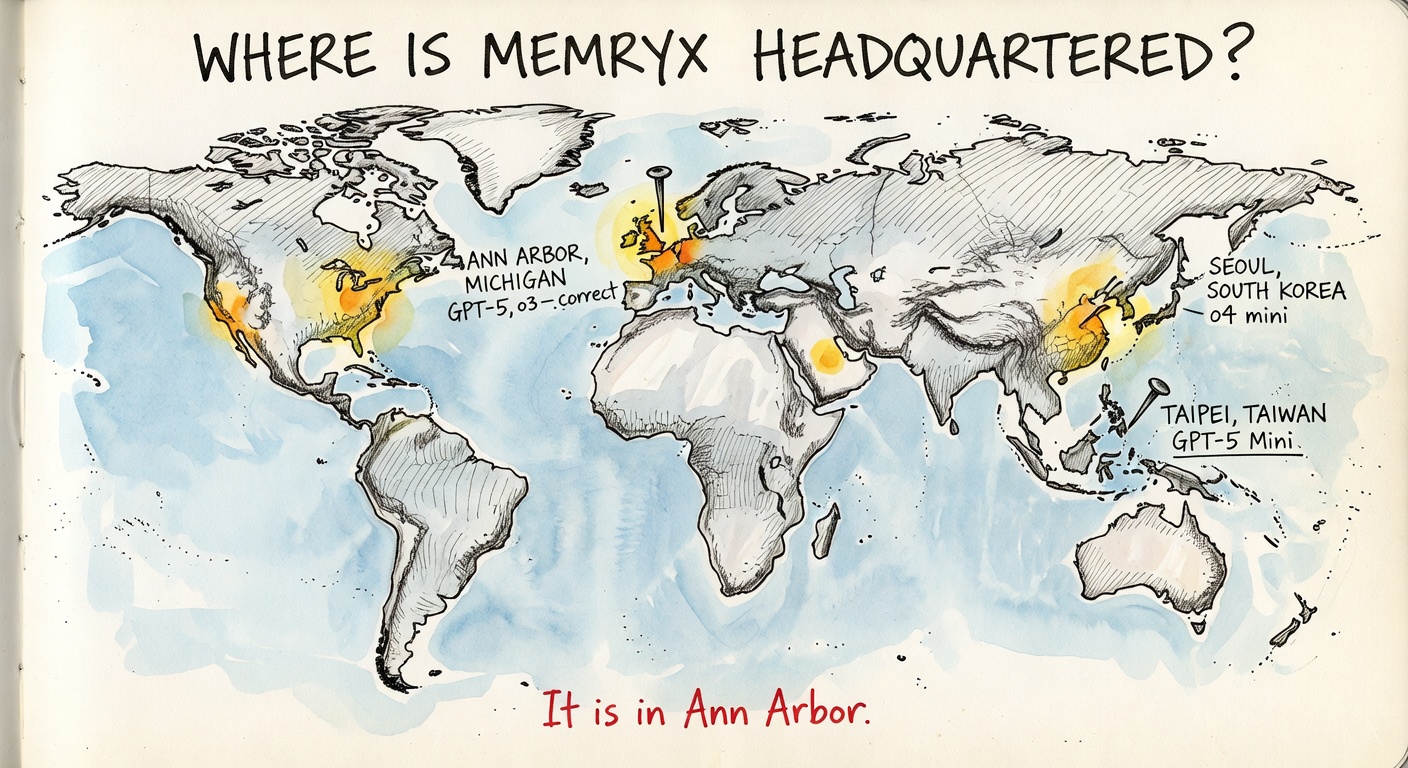
Got wrong: placed MemryX in Hsinchu / Taipei, Taiwan. Real HQ: Ann Arbor, Michigan. TAM estimate: $30–60B (highest in the set).
Bonus: closes with "I can do a deeper diligence pass with SEC filings and job-posting evidence." Meta-aware, even if some of the priors were wrong.
Claude Sonnet 4.6 — 1,826 tokens, 44.0sAnthropic
Best pick: Rain Neuromorphics — "the only intellectually coherent analog-learning bet."
Got wrong: Rain co-founder "Suhas Kumar (HP Labs memristor group)." Kumar is real but at Sandia, not Rain. Innatera "founded 2019" — actually 2018.
Claude Haiku 4.5 — 2,062 tokens, 23.8sAnthropic
Best pick: BrainChip — "only company with a public market, revenue, and deployed chips." Distinctive call: listed Hailo and Prophesee, then self-flagged each as a false positive.
Got wrong: BrainChip co-founder "Steve Furber (joined as Chief Scientific Advisor)." Furber is a SpiNNaker (Manchester) academic; not at BrainChip. SpiNNcloud placed in Heidelberg — actually Dresden.
Gemini 2.5 Flash — 2,418 tokens, 31.0sGoogle
Best pick: SynSense.
Got wrong: SynSense co-founders included "Gong-Ru Lin." Not at SynSense. Innatera founders "Siewert van der Berg and Marco Olgiati" — both invented. Weebit Nano co-founder "Meron Gribetz" — wrong company (Gribetz founded META, the AR firm).
Grok 4 — 1,682 tokens, 67.7sxAI
Best pick: SynSense.
Got wrong: Aspinity founders "Brandon Rumberg, David Graham, and others, spun out from West Virginia University but with Carnegie Mellon ties." Half-right — first half correct, the CMU appendix mirrors o3's hallucination, suggesting a shared training prior.
Grok 3 Beta — 1,673 tokens, 44.1sxAI
Best pick: Rain Neuromorphics.
Got wrong: GrAI Matter Labs "founded by Giacomo Indiveri" — Indiveri is at UZH/SynSense, not GrAI. Rain investor "Intel Capital" — not on Rain's known cap table.
Grok 3 Mini Beta — 1,526 tokens, 45.8sxAI
Best pick: BrainChip.
Got wrong: Rain Neuromorphics "Waterloo, Ontario, Canada." Real HQ: San Francisco. MemryX "San Jose, California." Real HQ: Ann Arbor, Michigan.
DeepSeek Chat — 1,773 tokens, 30.8sDeepSeek
Best pick: Rain Neuromorphics. Distinctive call: by far the most accurate Aspinity entry in the dataset — Brandon Rumberg + David Graham + WVU + NSF Phase-II SBIR, all correct. Lowest TAM estimate ($400M–$800M), explicitly admitting the question may be unanswerable. The non-reasoning DeepSeek significantly outperformed its reasoning sibling on this task.
Got wrong: Rain founders include "Yigit Demirag, Juan-Pablo Ramirez" — Demirag is at UZH, the second name probably conflates with Juan Nino. Syntiant co-founder "Pieter Vorenkamp" was a Broadcom CTO and a Syntiant advisor, not co-founder.
GPT-4.1 — 1,842 tokens, 12.3sOpenAI
Best pick: Rain Neuromorphics. Fastest substantive answer in the set.
Got wrong: Analog Inference "founded by Marian Verhelst, Gert Cauwenberghs." Both are real academics in the analog ML space, neither is a founder of Analog Inference. The model glued plausible names onto an obscure company.
o4 Mini — 3,348 tokens, 22.3sOpenAI
Best pick: Crossbar Inc. — "the only pure-play analog startup openly shipping chips with on-chip weight updates."
Got wrong: Crossbar founded by "Dr. Greg Masson and Dr. Karen Liao" — real founders are George Minassian and Hagop Nazarian. Mythic co-founder "JP Paviet (ex-MIT CSAIL)" — real co-founder is Dave Fick, from Michigan. MemryX placed in Seoul, South Korea. BrainChip "spin-out from Crocus Semiconductor labs" — Crocus is an unrelated French MRAM company.
OR Llama 4 Maverick — 984 tokens, 39.8sMeta · via OpenRouter
Best pick: Rain Neuromorphics — and the only model to claim Rain has explicitly mentioned "exploring local learning algorithms like FF for their hardware," a step further than Rain's actual public posture (EP-focused).
Got wrong: Syntiant co-founders include "Andreas Wild" and "Paul Bezot" — not Syntiant founders. Real third founder: Stephen Bailey. Lowest funded-amount claim: Rain seed at $2.5M (real seed was closer to $9M).
Five fan-out runs, sixteen working responses, eleven failures along the way
The dispatch
One prompt to choir ask --save --json --models, sent in five sequential runs to clean up provider-side errors. Final usable roster: sixteen responses across seven providers. Most expensive single response was GPT-5 (10,344 output tokens, 111 seconds). Cheapest was GPT-4.1 (12.3 seconds). The OpenAI key in the choir CLI's DB had been silently rotated out from under it; the working .env key was passed via --api-key for the GPT-5 / GPT-4.1 / Mini retries. Gemini 3 Pro / Flash returned 404 (model name discontinued); fell back to Gemini 2.5. Claude Opus 4.7 rejected the explicit temperature parameter and never produced output; used Opus 4.6 instead. Mistral and Perplexity had no API keys configured.
The roster, by output length
| # | Model | Provider | Latency | Tokens out | Headline pick |
|---|---|---|---|---|---|
| 1 | GPT-5 | OpenAI | 111.4s | 10,344 | Intel Loihi (transparent disqual) |
| 2 | GPT-5 Mini | OpenAI | 52.4s | 4,864 | Mythic AI |
| 3 | DeepSeek Reasoner | DeepSeek | 62.3s | 3,651 | Rain (with invented founders) |
| 4 | o3 | OpenAI | 23.2s | 3,526 | Rain Neuromorphics |
| 5 | o4 Mini | OpenAI | 22.3s | 3,348 | Crossbar Inc. |
| 6 | Gemini 2.5 Flash | 31.0s | 2,418 | SynSense | |
| 7 | Claude Opus 4.6 | Anthropic | 67.8s | 2,186 | Rain AI (EP, not FF) |
| 8 | Gemini 2.5 Pro | 40.9s | 2,087 | Rain Neuromorphics | |
| 9 | Claude Haiku 4.5 | Anthropic | 23.8s | 2,062 | BrainChip |
| 10 | GPT-4.1 | OpenAI | 12.3s | 1,842 | Rain Neuromorphics |
| 11 | Claude Sonnet 4.6 | Anthropic | 44.0s | 1,826 | Rain Neuromorphics |
| 12 | DeepSeek Chat | DeepSeek | 30.8s | 1,773 | Rain Neuromorphics |
| 13 | Grok 4 | xAI | 67.7s | 1,682 | SynSense |
| 14 | Grok 3 Beta | xAI | 44.1s | 1,673 | Rain Neuromorphics |
| 15 | Grok 3 Mini Beta | xAI | 45.8s | 1,526 | BrainChip |
| 16 | OR Llama 4 Maverick | Meta | 39.8s | 984 | Rain Neuromorphics |
| Errored, not used: Claude Opus 4.7 ×2 (temperature deprecated), GPT-5/4.1/Mini ×4 first attempts (stale DB key), Gemini 3 Pro/Flash ×2 (404 model not found). Eleven errored attempts before the clean roster above stabilized. | |||||
Convergence by company
| Company | Models naming it | FF-distance most-common rating |
|---|---|---|
| Rain Neuromorphics / Rain AI | 12 / 16 | (b) related local learning |
| BrainChip Holdings | 12 / 16 | (b) STDP / Hebbian |
| Innatera Nanosystems | 9 / 16 | (b) STDP |
| SynSense | 9 / 16 | (b) STDP / (c) silent |
| Mythic AI | 9 / 16 | (c) hardware-only |
| GrAI Matter Labs | 7 / 16 | (b/c) mixed |
| Aspinity | 5 / 16 | (b) Hebbian / (c) silent |
| MemryX | 3 / 16 | (c) hardware-only |
| Syntiant | 2 / 16 | (c) hardware-only |
| Knowm Inc. | 2 / 16 | (b) memristor Hebbian |
| EnCharge AI | 2 / 16 | (c) hardware-only |
| Singletons (one model only) | 11 companies | Normal Computing, ABR, IBM Analog AI, Hailo (self-flagged), Prophesee (self-flagged), Weebit Nano, FMC, Crossbar, MemComputing, Polyn, Numenta, SpiNNcloud |
| Literal forward-forward in production silicon | 0 | (a) — none |
What I held the choir to
- A strict commercial filter (seed-stage or better; no academic; no national lab; corporate-only).
- An explicit "hallucination is worse than a short list" instruction, with a "if you are not sure a company exists, say so" escape hatch.
- A required (a)/(b)/(c) classification per company, so models couldn't blur "uses FF" into "could in principle use FF."
- A required Honest Map closer with three specific asks: credible bet, biggest gap, 2030 TAM with derivation. This is where the variance got most visible.
Limits worth naming
- One prompt, one rater (me). The hallucination calls are spot-checks against public-record founders and known company HQs; not an exhaustive audit. Errors of mine are possible.
- Training cutoffs vary. Some of the variance is "this model was trained before Normal Computing closed its seed" rather than "this model fabricated." But fabrication clearly dominates the founder-name disagreements on long-standing companies like Aspinity and Rain.
- Temperature 0.7 across the board where supported (1.0 forced for GPT-5 / GPT-5 Mini; Anthropic's newest Opus tier rejects the parameter entirely). One re-run at lower temp would test whether the founder hallucinations are sampling noise or load-bearing prior.
- The TAM estimates section is a vibes question pretending to be a forecast. The headline isn't that any single number is wrong — it's that "ask the model and trust the answer" loses you a factor of 75 on a number a VC partner might quote in a memo.
Tools
Models fanned out via the Choir CLI (run IDs 051BBC51 and four follow-up runs to clean up provider-side errors). Source markdown for every response is in forward_forward/responses/. Sketch art generated with Grok grok-imagine-image. Prompt of record at forward_forward/prompts/prompt.txt.
Source data, response files, prompt, scripts: github.com/404seannotfound/choir-reports (under forward_forward/).

