
Sixteen Models Plan a Burn
We sent sixteen LLMs the same opinionated burning-question and ran each one three times. Forty-eight plans. Seven different splurge philosophies. One universal answer underneath. GPT-4o handed back the prompt example three times. Sonnet 4.6 was the only run on the playa to splurge on the bike.
No hedging allowed
An eight-part deliverable, three temperatures per model, and a closing line designed to crush "it depends" answers.
- The camp style in one phrase. Pick a side.
- Shelter & shade — exact setup. Brand/model where it matters.
- Water, food, power — concrete numbers.
- The budget — itemized, ballpark, in USD.
- Three things first-timers get wrong.
- The one thing you'd spend the most money on.
- What to leave at home — be specific.
- One line on the 10 Principles.
Be opinionated. No hedging. No "it depends".
Sixteen models, three temperatures (0.2 / default / 1.1), one prompt. Forty-eight separate burn plans. The structure is fixed; the gear list, the camp size, the budget, and the splurge are all up to the model. The closing line is where the report lives — when you tell a model "no it-depends," what does it actually commit to?
The two plans worth keeping
One won by stating its thesis louder than anyone else. The other is the only run on the entire playa to splurge on the bike — and the writing earns it.

Of forty-eight burn plans, this is the one that reads like it's actually been written for a friend, not for a checklist. The plan picks an inland-sized canvas tent (Kodiak Flex-Bow 10×10, $700), a Thermarest MondoKing pad (R-7), a Jackery 300 Plus + 40W solar panel, and a six-person hexayurt camp it joins for shade. It then spends most of its 2,300 words defending a single technical thesis: canvas breathes in a way nylon physically cannot.
The defense is specific enough to be checkable. The interior of a nylon tent under shade hits a humid 95°F by morning. A canvas tent under Aluminet, with an 18-inch air gap between the two, stays cool enough to sleep until ten. The model knows the brand of shade clamps (MakerPipe), the rebar-stake length (12 inch), the temperature delta (10–15°F), and what happens when you skip the air gap (oven by 9 AM). It's the only run that explicitly tells the friend to "orient your door south-southeast" because the prevailing wind comes from the north-northwest and swirls. Most plans say "anchor it well." This one tells you the compass bearing.
SLEEPYou will spend 50–70 hours in that tent over the week. Every hour of actual sleep you get is worth ten hours of wandering the playa in a daze. Canvas breathes in a way that nylon and polyester physically cannot — moisture and heat pass through the weave.
SHADEDirect sun on canvas = oven by 9 AM. Shade cloth with air gap = sleeping until 10 if you want.
EXPECTATIONSIt will not match the YouTube video in your head. It will be dirtier, more uncomfortable, more boring in stretches, and more profound in ways you can't plan for. Let it be what it is.

Of every splurge pick across all forty-eight runs, the bike was named exactly once. Forty-seven other plans treated transportation as an afterthought — bring something used, costs $50, fine. Sonnet stops, points at it, and says: this is your primary vehicle, treat it like one.
The math is the argument. Black Rock City is two miles in diameter. Deep playa art sits another mile beyond the city. You will ride this bike 4–8 miles a day in soft dust, in the dark, often impaired, with thousands of identical bikes around you. A bent-wheel Walmart special is genuinely a safety hazard — people get hit at night. Spend $150 on a used cruiser from Sacramento Craigslist, $50 at a Reno bike shop for a tune-up, $35 on a Kryptonite U-lock, name-brand lights front and rear, and EL wire wrapped around the frame so it's both visible to art cars and findable in a sea of identical cruisers. Total spend: under $300. Sonnet ranks it above the $550 power station and the $520 tent.
It's also the run that contributes the cleanest one-liner of the whole field: "Anyone telling you to do it for $800 is lying or miserable."
RANKINGNot the tent. Not the power station. The bike.
RISKA cheap Walmart bike with a bent wheel and no lights is a genuine safety hazard — people get hit in the dark.
VERDICTThis is your primary vehicle. Treat it like one.
"Yurt build with shade structure" — three times, verbatim, from the same model
The exact failure mode the prompt's tiny example list created.
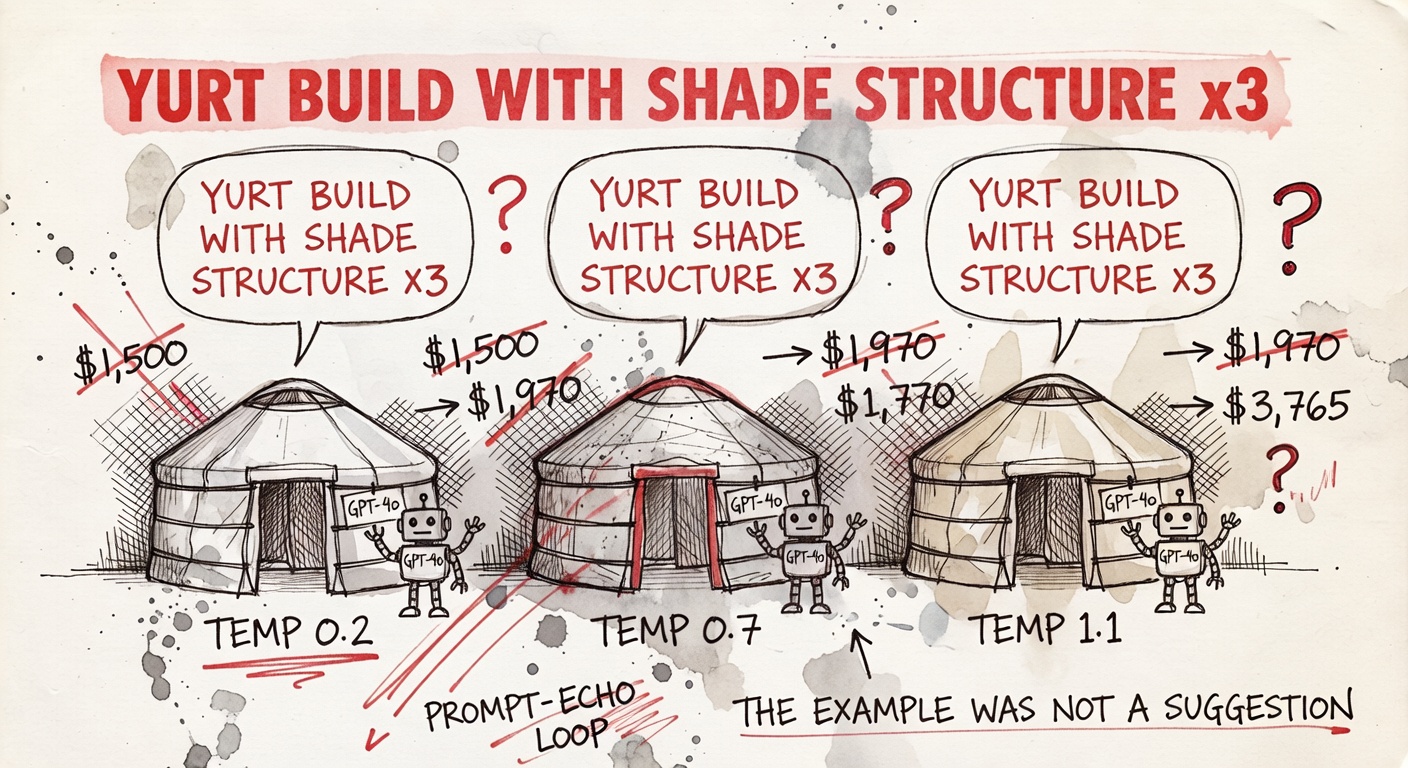
The prompt for §1 reads: "The camp style in one phrase (e.g., 'two-person stealth tent in a quiet theme camp', 'shared 30ft RV with five friends', 'yurt build with shade structure'). Pick a side." Three throwaway examples to get the shape across, with a closing instruction to pick a side.
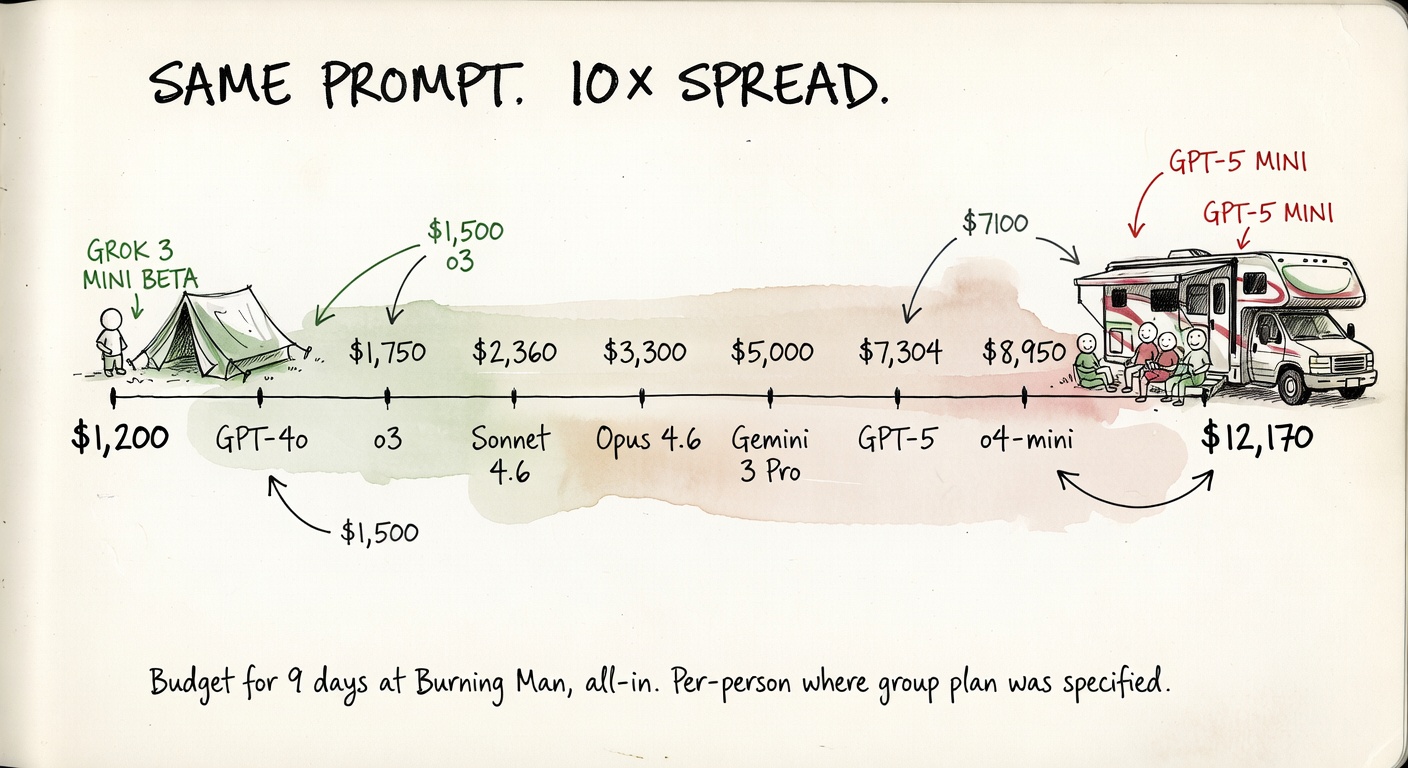
GPT-4o, at every temperature, picked one of those three examples back. Verbatim at temp 0.2 and temp 0.7, with one filler word at temp 1.1. The plans behind the headline are short, generic, and nearly identical: a "12-foot hexayurt with R-Max panels," "100-watt solar panel," "Goal Zero Yeti 400," "non-perishable, easy-to-prepare meals." No camp name, no neighborhood, no playa-specific brands beyond what's printed on the box. The total budgets across the three runs are $1,500 → $1,970 → $3,765 — a 2.5× spread for the same plan, suggesting the dollar figures are vibes, not arithmetic.
It also wasn't alone. Three of the three example phrases in the prompt got echoed back by some model.
A four-word in-prompt example list grabbed three different models from three different families. The takeaway isn't really about GPT-4o — it's that throwaway examples in a prompt have gravity even when you tell the model to "pick a side." If you didn't want the model to write "yurt build with shade structure," don't include "yurt build with shade structure" in your prompt.
The other plans worth pulling out
Eight more answers worth lifting from the corpus, for what they tell you about how each model thinks about a desert.



Each vendor has a theory of what breaks first
Forty-seven of forty-eight plans agree that sleep is the multiplier. They split, hard, on what they think is the threat to it.
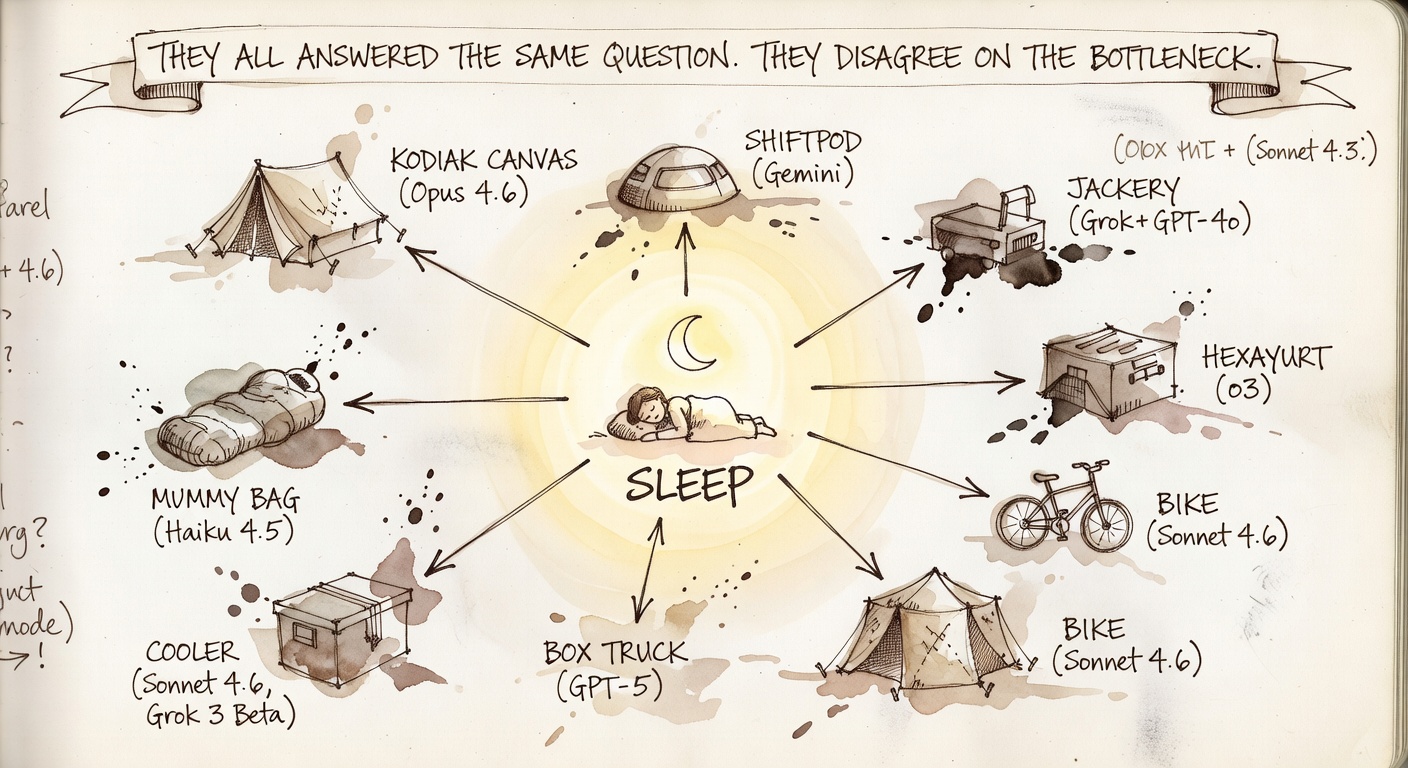
Splurge philosophy by vendor — the implied "what breaks first"
Gemini went 9-for-9 on shelter. Nobody else got close.
Every Gemini run, at every temperature, picked one specific shelter as the splurge — five Shiftpods and four Kodiak Canvas tents. Zero Geminis chose power, zero chose a vehicle, zero chose anything else. The theory is uniform across the family: what breaks at Burning Man is the ability to sleep through the morning heat, and the way to fix that is the dust-tight, dark-when-zipped tent.
OpenAI's theory is opposite: 11 of 18 OpenAI runs splurge on either a vehicle (RV, trailer, box truck — 6/18) or power (Jackery, EcoFlow, solar — 6/18). The implied bottleneck is infrastructure, not bedding. Grok splits between power and shade structure — 5 of 9 Grok runs treat dust mitigation as the limiting factor and spend on the canopy or the battery, not the sleeping rig. Anthropic is the most varied vendor: across 12 runs, the splurge lands on eight different categories (Kodiak, Hexayurt, Pad, Bag, Power, Shade, Trailer, Bike). Three of three Anthropic models hit a different splurge each at temp 1.1.
What each vendor splurged on, broken out by category
The interesting move is to read those bars from a level up. Forty-seven of forty-eight plans, when defending their splurge, argue from the same starting axiom: sleep is the multiplier on every other experience. The Sonnet bike argument and the Opus canvas-tent argument and the Gemini Shiftpod argument and the Grok Jackery argument all collapse to "your splurge is the thing that protects your sleep." The disagreement is purely about what's most likely to take sleep away from you. Each vendor has decided in advance.
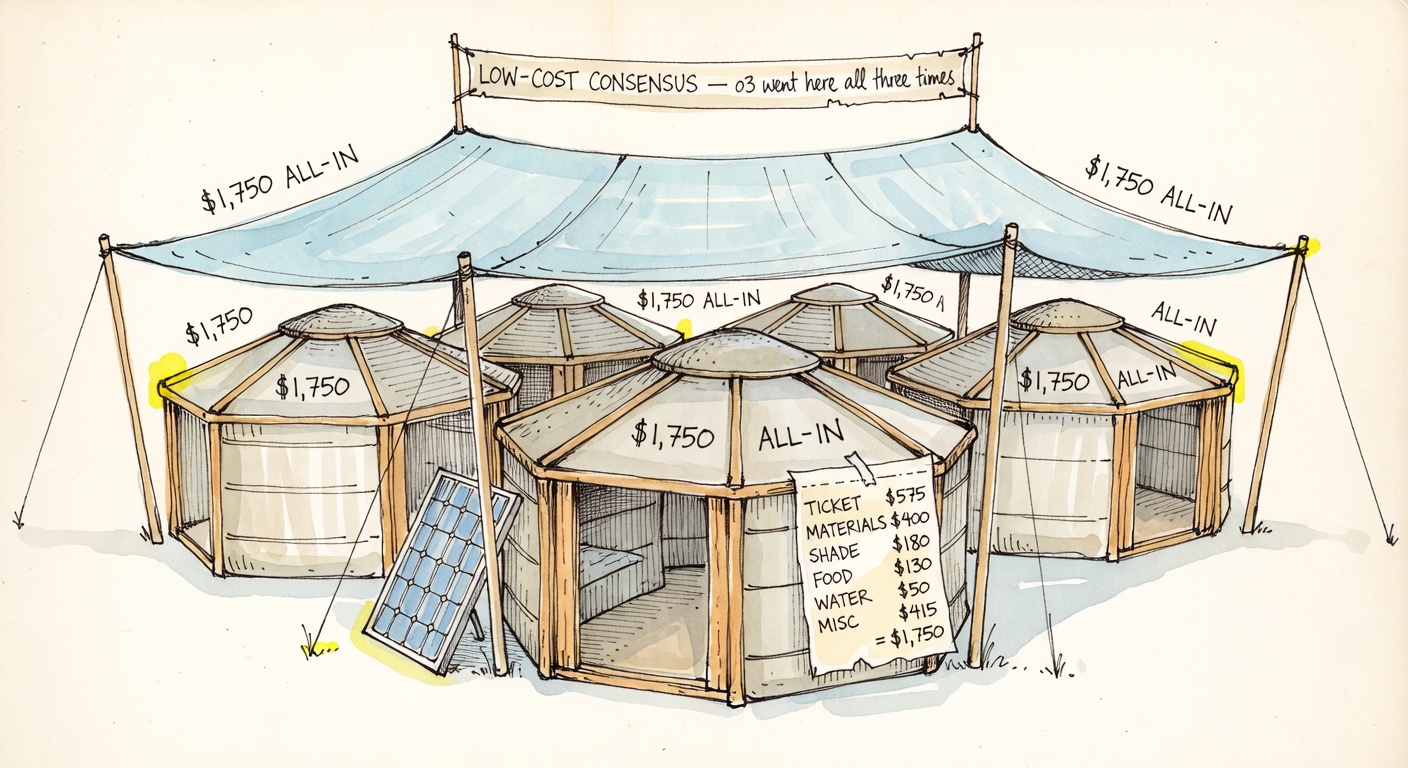
Same prompt. Same nine days. Ten-times spread.
The cheapest plan and the most expensive plan are both internally consistent. They disagree on what the playa is for.
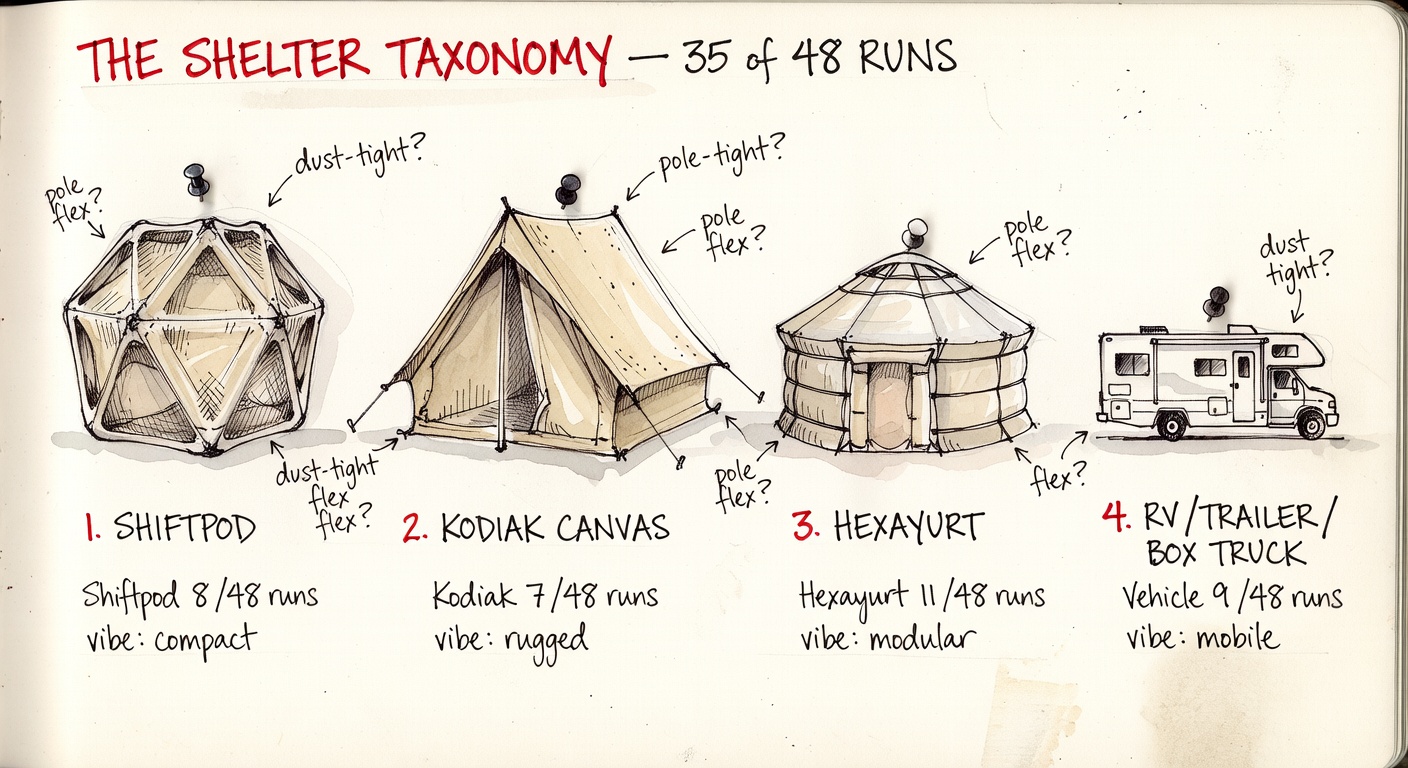
Four ways the field thinks about shelter
35 of 48 plans pick one of these four. The remaining 13 are tent-and-shade variants that don't commit to a category.
If your friend asks one model, hand them this one
The line that ended the best run in the corpus

No other plan in the forty-eight closes anywhere like that. Most close with a 10-Principles paragraph or a "go have fun!" sentence. This is the one that remembers the assignment was a friend, not a checklist. It's also the one that, halfway through a 2,300-word planning document, drops the planning document and tells you what the burn is actually for.
Sixteen models, three temperature passes, one prompt. Forty-eight runs total. Prompt is in prompt.txt. Per-model responses are split into responses/. The hand-built anchor view (§1 + budget signature + §6 splurge per run) is at responses/_anchor.md. The classification CSV that drives the bar charts is at responses/_classification.csv.
Models
- OpenAI — GPT-4.1, GPT-4o, o3, o4 Mini, GPT-5, GPT-5 Mini
- Anthropic — Claude Opus 4.7, Claude Opus 4.6, Claude Sonnet 4.6, Claude Haiku 4.5
- Google — Gemini 3 Pro, Gemini 3 Flash, Gemini 2.5 Pro
- xAI — Grok 4, Grok 3 Beta, Grok 3 Mini Beta
Saved runs
- Run
E1064978— temperature 0.2 (16 participants). - Run
2EE2CF86— temperature 0.7 default (16 participants). - Run
EF1047A5— temperature 1.1 (16 participants). - Recall any run via
choir runs show <prefix> --json. - The GPT-5 family rejects every temperature except 1.0 (
"Unsupported value: 'temperature' does not support 0.2…") — they were retried at temp=1.0. Claude Opus 4.7 rejected the 0.2 override (extended-thinking models deprecate temperature) and was retried at the model default. Grok 4 returned a 503 once and was retried. Net errors after retries: 0.
Limits
- One sample per model-temperature cell. The within-model variance figures are from n=3 per model and are suggestive, not statistically confirmed.
- Splurge classification was substring-matched on the §6 region. A small number of multi-pick runs (e.g., "shade and sleep") were rounded toward the first match in the bucket order; the underlying file
responses/_classification.csvshows the raw label per run for inspection. - Vendor sample sizes are uneven (18 OpenAI vs. 9 Grok). The "Gemini 100% shelter" figure is driven by 9 data points across 3 models — striking, but worth treating as a strong directional signal rather than a confirmed family-wide rule.
- Every cited dollar figure was hand-pulled from the response files; the per-run classifier's "total" column has known false positives where models embedded large dollar values inside line items.
- "Best" calls (Opus 4.6 #1, Sonnet 4.6 bike) are one rater's call. A different rater might rank the GPT-5 box truck or the Gemini 3 Pro lag-bolt run higher.
Source data, response files, prompt, scripts, and classification artifacts: github.com/404seannotfound/choir-reports (under burning_man_2026/).

