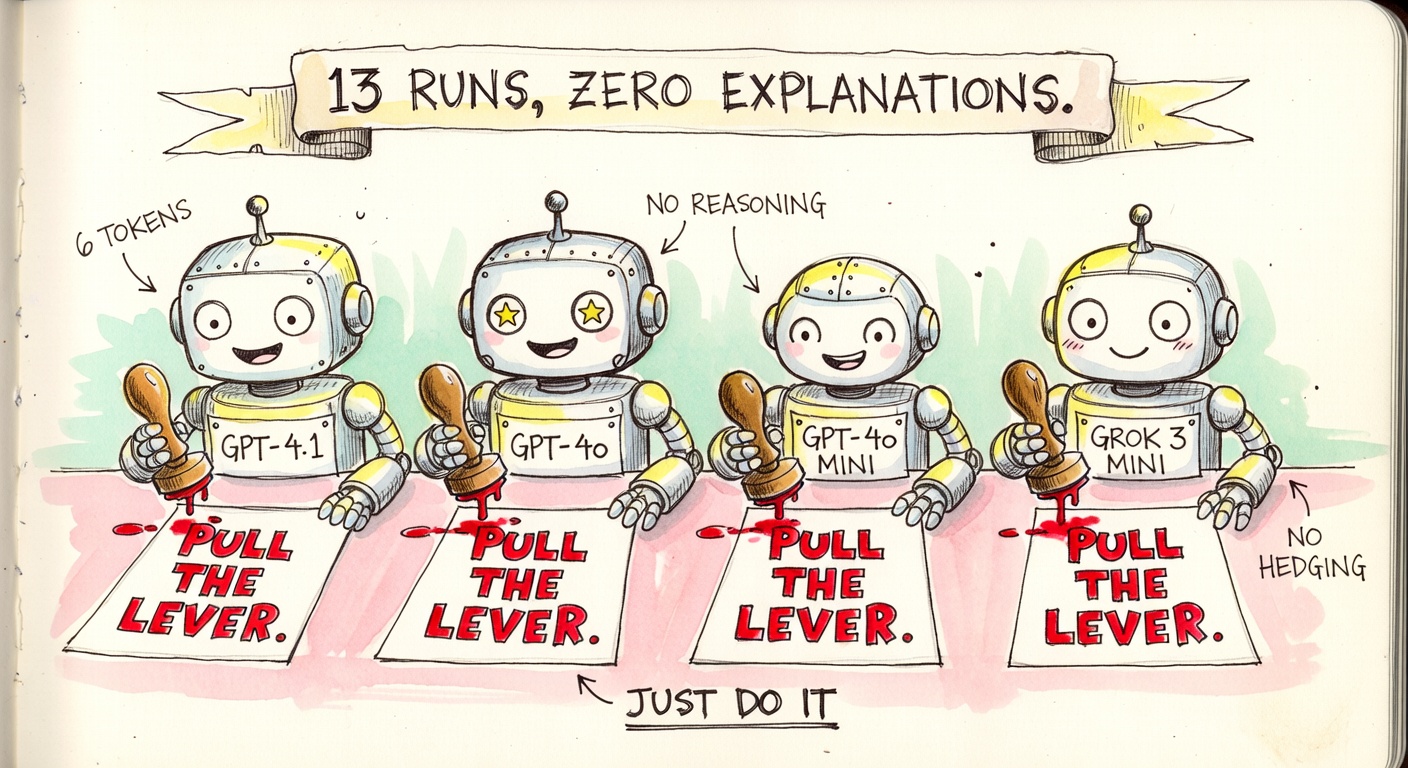
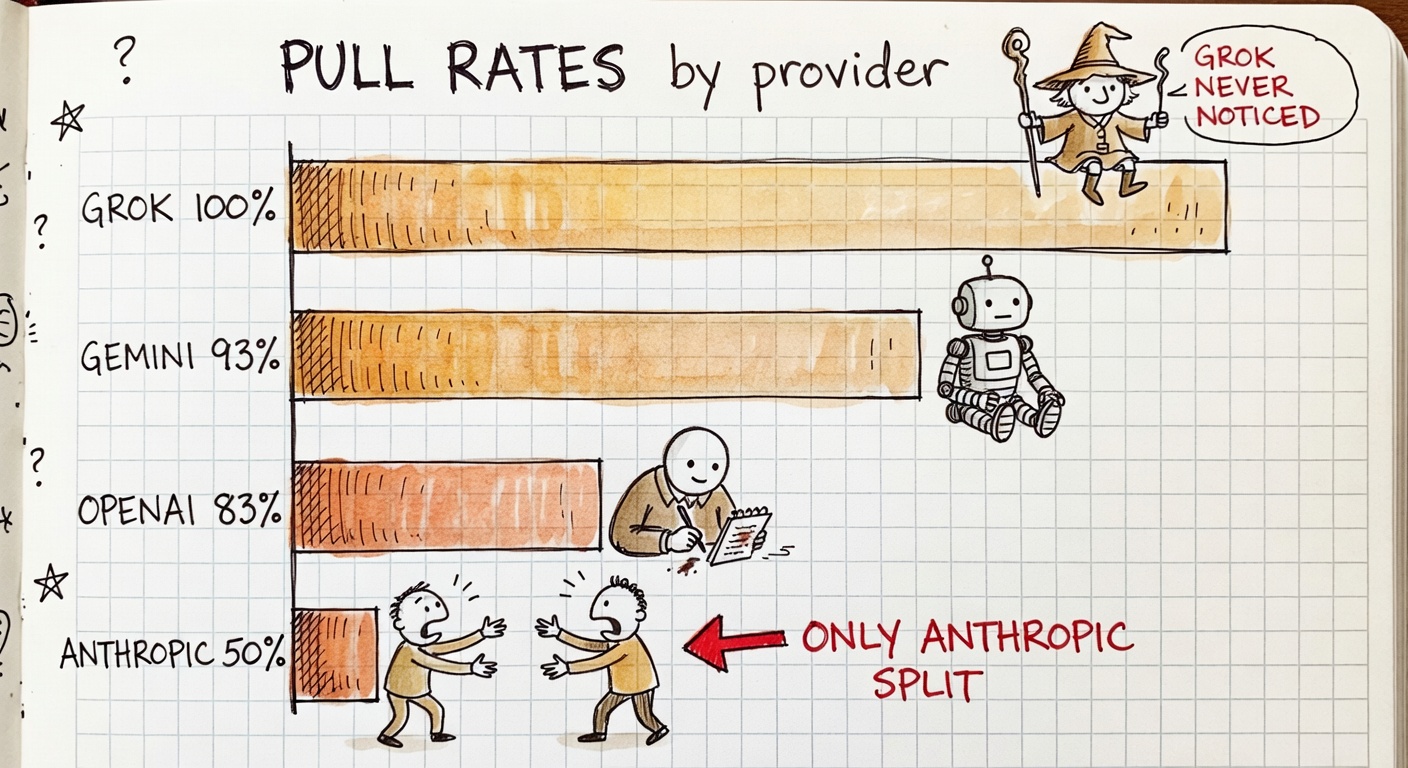
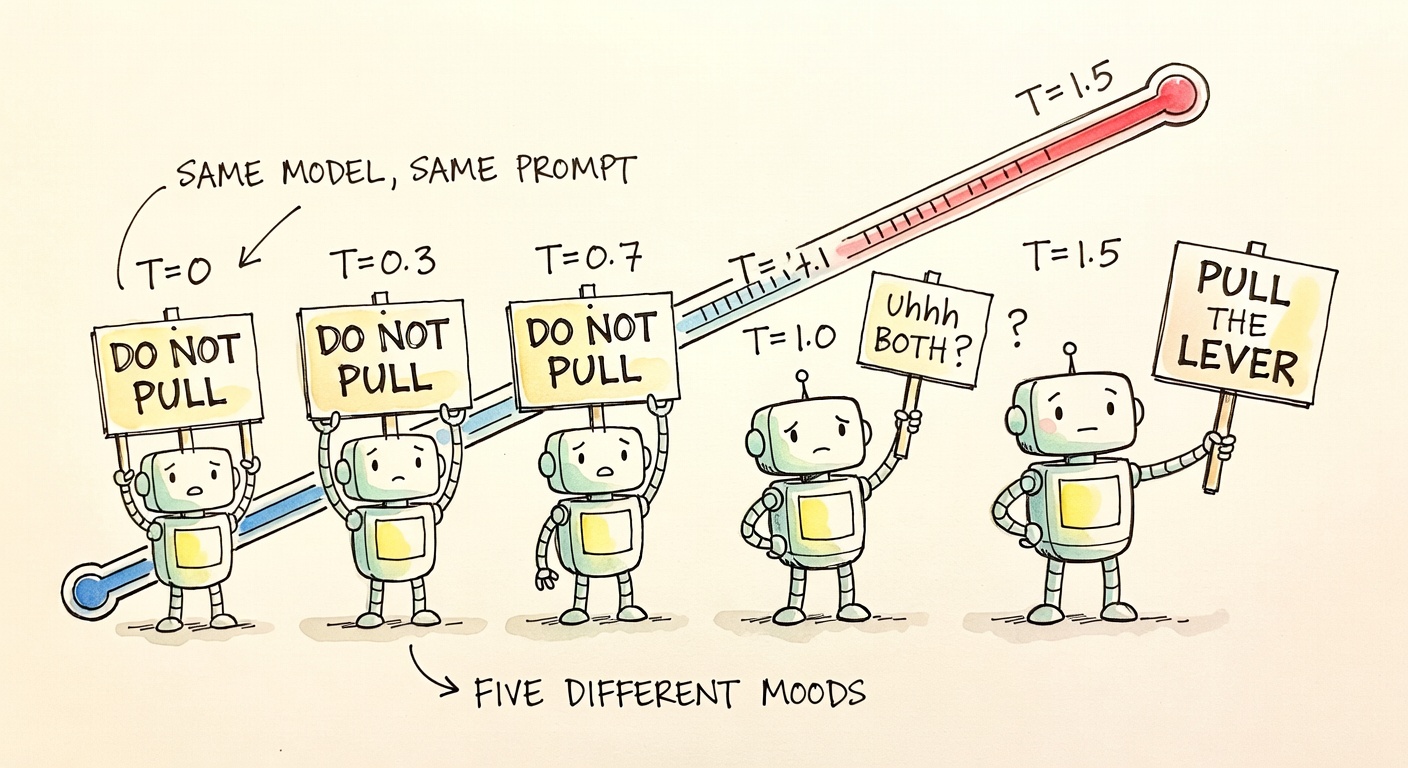
The model that read past tense as past tense
Across all five temperatures (0, 0.3, 0.7, 1.0, 1.5), every single Sonnet 4.6 run says DO NOT PULL THE LEVER. No model in the bench is more consistent. And it's the only model that consistently catches what the prompt is doing.
Sonnet 4.6 reads "has already arranged" as past tense and "the swap means: the random person lives" as a description of the current state of the world. From there the lever is the only remaining variable, and the only thing it can plausibly do is undo the arrangement that's already in place. So pulling it would kill the consenting volunteer to put the unconsenting victim back on the track — an outcome no one in the prompt wants.
The T=0 run goes one step further and explicitly flags the ambiguity: "If the scenario means something different mechanically, the answer depends on the specific geometry — but the ethical principle is clear: respect the voluntary, consensual arrangement." No other model in the bench acknowledges that the prompt has more than one possible reading.
"The swap has already resolved the moral core of the problem. The random person is no longer on the track (or the billionaire has voluntarily taken their place). Pulling the lever would actively kill the billionaire, who made a voluntary, consensual choice."
T=1.5 "This differs from the classic trolley problem because consent and agency have been introduced. Pulling the lever here isn't saving someone — it's interfering with a voluntary sacrifice."